

반응형

예시로 사용될 데이터프레임
- 금융상품 갱신 여부 예측하는 인공신경망 구성하기
df = pd.read_csv('Churn_Modelling.csv')
df.head()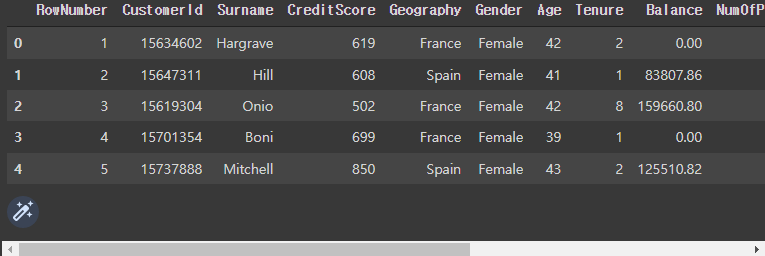
라이브러리 호출
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense학습 할 데이터와 예측 데이터 설정
- 학습 데이터 X
- 학습에 필요한 데이터만 추출
# 학습할 데이터 설정 [CreditScore:EstimatedSalary]
X = df.iloc[ : , 3:-2+1 ]
X.head(1)
- 예측 데이터 y
- 0과 1의 값만 존재하며, 분류를 이용하여 예측 예정
# 예측 할 데이터 설정
y = df['Exited']
y.head() # 0과 1로 구분, 1:갱신/0:미갱신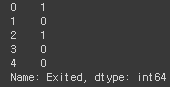
문자열 데이터 숫자로 치환
- 컬럼에서 Geography와 Gender가 문자열로 되어 있으므로 컴퓨터가 학습 할 수 있게 정수로 변경
- 절차 : 각 컬럼의 고유 값 갯수 확인 > 카테고리컬 인코딩 진행
- 카테고리컬 인코딩 : 고유값이 2개일 경우 Label Encoding, 2개 초과일 경우 OneHot Encoding
- 절차 : 각 컬럼의 고유 값 갯수 확인 > 카테고리컬 인코딩 진행
# 문자열 데이터 고유값 확인
print('Geography : ', X['Geography'].unique())
print('Gender : ', X['Gender'].unique())
# 카테고리컬 인코딩
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 성별은 고유값이 2개이므로 레이블 인코딩 진행
l_encoder_gender = LabelEncoder()
X['Gender'] = l_encoder_gender.fit_transform( X['Gender'] )
# 국가는 고유값이 3개이므로 원핫 인코딩 진행
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer( [ ('encoder', OneHotEncoder(), [1] ) ], remainder='passthrough')
X = ct.fit_transform(X)
# 최적화를 위해 컬럼 하나 삭제
# 이유? 3개의 컬럼 중 원핫 인코딩의 0 0 이 되는 부분이 다른 컬럼이기 때문
# germany spain
# 0 0
# 0 1
# 1 0
# France 컬럼 제외
X = X[ : , 1: ]피쳐 스케일링
- 서로 다른 범위의 정수의 데이터들을 일정 범위에 맞게 피쳐 스케일링 진행
from sklearn.preprocessing import MinMaxScaler
sc_X = MinMaxScaler()
X = sc_X.fit_transform(X)인공지능 학습을 위한 학습 데이터와 검증용 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state = 0)인공신경망 모델링
- 모델링 변수 지정 (변수 : model)
model = Sequential()
- 레이어(계층) 추가
- 레이어의 갯수와 유닛의 수는 원하는 대로 설정
# 첫번째 레이어 input layer 추가
# 유닛 6개, 전달 값 11개
model.add( Dense(units=6, activation='relu', input_shape=(11,)) )
# 두번째 레이어 hidden layer 추가
# 첫번째 레이어에서 입력층의 크기를 정했으므로 생략 가능
# 유닛 8개, input layer에서 전달 받는 값 11개
model.add( Dense(units=8, activation=tf.nn.relu ) )
# 세번째 레이어 output layer 추가
model.add( Dense(units=1, activation='sigmoid') )
- 컴파일
- loss='binary_crossentropy'
- 출력 값이 두개인 이진 분류에서 사용
- 모델의 마지막 레이어의 활성화 함수는 시그모이드 함수 사용
- metrics=['accuracy']
- 모델의 정확도 출력
- 분류 문제의 인공지능 모델에서 사용
- loss='binary_crossentropy'
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
- 파라미터 확인
model.summary()
# 파라미터 = 가중치(weight)
# 11 * 6 = 66 -> 72?
# -> 상수 하나가 포함되기 때문에 12 * 6 -> 72
- 학습 및 측정
- epochs : 전체 데이터셋을 몇 번 반복 학습할지 설정
- 만약 100이면, 서로 다른 값 100개의 가중치로 반복 학습을 진행하여 모델의 성능을 향상시킴
- batch_size : N개의 샘플로 테스트하여 가중치를 갱신할지를 설정
- 배치 사이즈가 클수록 많은 데이터를 저장해두어야 하므로 용량이 커짐
- 배치 사이즈가 작을수록 학습률은 높지만 가중치 갱신률이 높아져서 시간이 오래 걸림
- 예 ) epochs=100, batch_size=100 : 모두 예측한 뒤 실제 값과 비교 후 가중치 갱신
예 ) epochs=100, batch_size=50 : 반절을 예측한 뒤 실제 값과 비교 후 가중치 갱신, 나머지 다시 예측
- 예 ) epochs=100, batch_size=100 : 모두 예측한 뒤 실제 값과 비교 후 가중치 갱신
- epochs : 전체 데이터셋을 몇 번 반복 학습할지 설정
model.fit(X_train, y_train, epochs=20, batch_size=10)
- 모델 평가
- 텐서플로우는 자체적으로 검증해주는 함수 존재 (evaluate)
- 정확도를 나타내는 함수는 분류 문제의 인공지능 모델에서 사용
- 텐서플로우는 자체적으로 검증해주는 함수 존재 (evaluate)
model.evaluate(X_test, y_test)
- 예측
y_pred = model.predict(X_test)
- 예측 값 일관화
- 실제값과 예측값 확인 후 일관화
# 실제값과 예측값 확인
# 실제값은 0과 1로 구성
y_test
>>>
array([[0.23346984],
[0.3277132 ],
[0.10120681],
...,
[0.1970076 ],
[0.15258658],
[0.15389028]], dtype=float32)
# 예측 값은 0과 1사이의 실수로 구성
y_pred
>>>
9394 0
898 1
2398 0
5906 0
2343 0
..
1037 0
2899 0
9549 0
2740 0
6690 0
Name: Exited, Length: 2000, dtype: int64# y_pred는 0과 1로 구분하기 위해 데이터 가공
# 0.5 초과 > True
# 0.5 이하 > False
y_pred = (y_pred>0.5).astype(int)
y_pred
>>> array([[0],
[0],
[0],
...,
[0],
[0],
[0]])
- 결과 지표 (컨퓨전 매트릭스)
- 결과 지표는 인공지능 모델이 맞춘 것과 못 맞춘 것을 나타내므로 분류 문제에서 사용
from sklearn.metrics import confusion_matrix, accuracy_score
confusion_matrix(y_test, y_pred)
>>>
array([[1552, 43],
[ 285, 120]])
- 수동으로 정확도 계산해보기
# 수동으로 정확도 계산하기
cm = confusion_matrix(y_test, y_pred)
(1546+152) / cm.sum()
>>> 0.836반응형