

개요
구글이 2024년 2월 21일에 Gemma를 공개했다.
Gemma는 구굴의 AI인 Gemini의 경량화 버전이다.
Gemma의 장점은 오픈 소스라는 것이다!
즉, 누구나 사용할 수 있다.
Google의 오픈 소스 AI 모델을 사용하려면 Kaggle, Hugging Face, Nemo, Vertex AI 등을 통해 사용할 수 있다.
이번 포스팅에서는 Hugging Face에서 Gemma 모델을 사용하는 방법을 다룬다.
[ 젬마와의 대화 내용 미리 보기 ]
Q : 당신에 대해 알려주세요
A : 저는 미국에서 온 20살 학생입니다. 저는 현재 캘리포니아 대학교 버클리에서 공부하고 있습니다. 저는 정치학을 전공하고 경제학을 부전공하고 있습니다. 저는 또한 버클리 모델 유엔 팀의 일원입니다.
Hugging Face 설정
Hugging Face 회원가입하기
허깅 페이스에 가입되어 있지 않은 경우에는 Gemma 모델을 사용할 수 없다.
바로가기 링크 : https://huggingface.co/
Hugging Face – The AI community building the future.
The Home of Machine Learning Create, discover and collaborate on ML better. We provide paid Compute and Enterprise solutions. We are building the foundation of ML tooling with the community.
huggingface.co
허깅 페이스 사이트로 이동하여 우측 상단의 Sign in 버튼을 눌러 회원 가입 후,
입력한 이메일의 가입 인증 메일을 확인하여 인증 진행한다.
Gemma 라이센스 승인하기
Hugging Face - Gemma Repo로 이동한다.
- 바로가기 링크 : https://huggingface.co/google/gemma-2b
google/gemma-2b · Hugging Face
This repository is publicly accessible, but you have to accept the conditions to access its files and content. To access Gemma on Hugging Face, you’re required to review and agree to Google’s usage license. To do this, please ensure you’re logged-in
huggingface.co
Acknowledge license 버튼을 클릭한다. (라이센스 확인)

Authorize 버튼을 클릭한다.

스크롤을 맨 아래로 내려 필수 항목 체크 후 Accept 버튼을 클릭한다.
사용자의 선택에 따라 필요 시 선택 항목도 체크한다.
- 필수 항목 : I accept the terms and conditions (약관에 동의합니다)
- 선택 항목 : I'd like to receive model updates, promotions, useful tips, and news about Google AI (구글 AI 관련 소식을 받고 싶습니다)

그러면 Gemma 모델에 액세스할 수 있는 권한이 부여됨을 확인할 수 있다.

Huggin Face 액세스 토큰 만들기
Gemma를 사용하려면 허깅 페이스의 액세스 토큰을 입력하여야 한다.
허깅 페이스의 사이트에서 우측 상단의 프로필을 누른 후, 'Settings' 메뉴를 선택한다.

Settings 페이지 왼쪽의 Access Tokens 메뉴를 선택한다.
Access Tokens 페이지에서 'New token' 버튼을 눌러 토큰을 생성한다.

- Name : 사용자 임의 지정
- Role : read

액세스 토큰이 생성되었다.
'Show' 우측의 네모 아이콘을 누르면 토큰이 복사된다.
토큰을 복사해두자.

파이썬 설정
파이썬이 사전에 설치되어 있어야 한다.
Hugging Face CLI 라이브러리 설치 및 로그인
Hugging Face CLI를 설치하려면 터미널에서 아래와 같은 명령어를 입력해주면 설치된다.
pip install -U "huggingface_hub[cli]"
이제 Hugging Face의 Gemma와 파이썬 코드로 상호작용하기 위해 Hugging Face에 로그인을 해야한다.
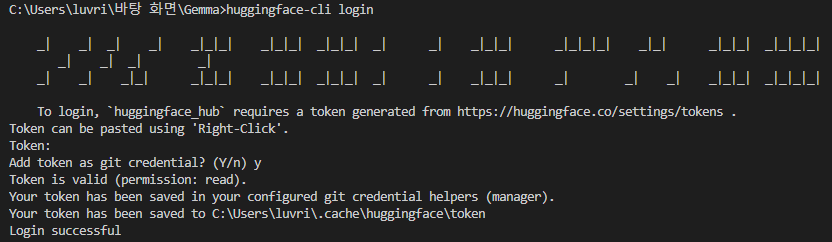
터미널에서 Hugging Face CLI 명령어를 이용하여 로그인을 진행한다.
huggingface-cli login
'Token: '이라는 글씨가 출력되고 토큰을 입력해야 한다.
복사해둔 액세스 토큰을 붙여넣기 후 엔터를 눌러 입력을 완료한다.
(토큰을 입력할 때 입력된 내용은 보이지 않는다. 당황하지 말고 붙여넣기 후 엔터를 누르자.)
Hugging Face Transformers 라이브러리 설치
Gemma를 사용하기 위한 자연어 처리를 위한 딥러닝 모델 및 관련 도구를 제공하는 라이브러리이다.
설치를 진행하면 모델에 따라 용량이 꽤나 차지하기 때문에 다소 시간이 소요될 수 있다.
pip install git+https://github.com/huggingface/transformers파이썬에서 Gemma 사용하기
Gemma 모델은 크게 두 가지로 나뉜다.
- 7B model : 매개변수가 70억개인 모델
- 2B model : 매개변수가 20억개인 모델
포스팅에서는 2B model을 사용하여 진행하였다.
CPU를 사용하여 Gemma 사용하기 [샘플 구문]
인공지능을 사용할 때 보통 CUDA(GPU)라는 것을 사용한다.
CUDA는 NVIDIA 그래픽 카드에서만 지원되기 때문에,
NVIDIA 그래픽 카드가 없는 컴퓨터에서는 CUDA라는 것을 사용할 수 없다.
보통 내장 그래픽인 경우에는 CPU만을 사용하여 인공지능을 사용해야 한다.
단, CPU만 사용하여 처리할 경우에는 처리 속도가 GPU를 사용 했을 때보다 현저히 느리다.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))GPU를 사용하여 Gemma 사용하기 [샘플 구문]
NVIDIA 그래픽 카드가 장착되어 있을 경우, GPU를 사용하여 Gemma 를 사용할 수 있다.
GPU는 병렬 처리 능력이 뛰어나기 때문에 CPU만을 사용하여 인공지능을 이용했을 때보다 훨씬 빠르다.
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))실제로 사용해보기
현재 작업하는 컴퓨터에서는 내장 그래픽을 사용하기 떄문에 CPU만을 이용하여 Gemma를 사용해야 한다.
새 파이썬 파일을 생성한 후, CPU를 사용하는 샘플 코드를 복사해서 파이썬 파일에 붙여넣자.
포스팅에서는 코드 에디터로 VS Code를 사용하였고, 새 파이썬 파일의 이름은 main.py로 지정하였다.

[ 질문 메시지 작성 ]
- input_text 부분에 질문할 메시지를 작성한다.
- 포스팅에서는 "Tell me about you" 라고 질문하였다.
[ Gemma의 답변 길이 설정 ]
- model.generate 두 번째 파라미터에 max_length 를 지정해준다.
- max_length를 지정하지 않으면 기본값인 20이 적용되며, Gemma가 20글자까지만 답변하고 내용이 짤려버린다.
- 답변이 생각했던 것보다 많이 느려서 포스팅에서는 100으로 설정하였다.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Tell me about you"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids, max_length=100)
print(tokenizer.decode(outputs[0]))
터미널에서 코드를 실행해보자.
python main.py
기다리다보면 답변이 생성된다. 포스팅에서는 길이를 100으로 설정하였기 때문에 내용이 짤려버렸다 ^^;;젬마가 역할 놀이에 진심인 것 같다.
