

목차
- 데이터 수집
- 데이터 수집 수행 자료
- 기초 데이터 수집 수행 절차
- 데이터 수집 시스템 구축 절차
- 비즈니스 도메인과 원천 데이터 정보 수집
- 비즈니스 도메인 정보
- 원천 데이터 정보
- 내/외부 데이터 수집
- 데이터 종류
- 데이터 수집 주기
- 데이터 수집 방법
- 데이터 수집 기술
- 데이터 유형별 데이터 수집 기술
- ETL(Extrac, Transform, Load)
- FTP(File Transfer Protocol)
- 정형 데이터 수집을 위한 아파치 스쿱(Sqoop) 기술
- 로그/센서 데이터 수집을 위한 아파치 플럼(Flume) 기술
- 웹 및 소셜 데이터 수집을 위한 스크래피(Scrapy) 기술
- 참고
반응형
데이터 수집
- 데이터 처리 시스템에 들어갈 데이터를 모으는 과정
- 여러 장소에 있는 데이터를 한 곳으로 모으는 것
데이터 수집 수행 자료
- 용어집
- 원천 데이터 소유 기관 정보
- 서비스 흐름도
- 데이터 수집 기술 매뉴얼
- 업무 매뉴얼
- 인프라 구성도
- 데이터 명세서
- 소프트웨어 아키텍처 개념도
- 데이터 수집 계획서 수집 솔루션 매뉴얼
- 원천 데이터 담당자 정보
- 하둡 오퍼레이션 매뉴얼
- 비즈니스 및 원천 데이터 파악을 위한 비즈니스 모델
기초 데이터 수집 수행 절차
- 비즈니스 도메인 정보 수집
- 전문가 인터뷰
- 인터뷰 결과 분석
- 분석기획서 기반 도메인, 서비스 이해
- 비즈니스 현황(이슈)
- 원천데이터 습득 현황
- 수집 데이터 탐색
- 수집 데이터 선정
- 데이터 위치, 유형, 수집 방법, 비용
- 기초 데이터 수집
- 체크 리스트
- 기초 데이터 수집
데이터 수집 시스템 구축 절차
- 수집 데이터 유형 파악
- 수집 세부계획서 정독
- 데이터의 종류 확인
- 수집 기술 결정
- 데이터 유형에 맞는 최적의 수집기술 선정
- 아키텍쳐 수립
- 수집 솔루션 아키텍쳐 파악
- 아키텍쳐 커스터마이징
- 하드웨어 구축
- 하드웨어 스펙 및 규모 결정
- 서버, OS, 스토리지 설치
- 실행환경 구축
- Sqoop, Flume 등 수집 솔루션 설치
비즈니스 도메인과 원천 데이터 정보 수집
비즈니스 도메인 정보
- 비즈니스 모델, 비즈니스 용어집, 비즈니스 프로세스로 부터 관련 정보 습득
- 도메인 전문가 인터뷰를 통해 데이터의 종류, 유형, 특정 정보 습득
* 비즈니스 프로세스 : 비즈니스 전개에 필요한 모든 순차적이거나 병렬적인 활동들의 집합
원천 데이터 정보
- 데이터 분석에 필요한 정보
- 원천 데이터의 수집 가능성
- 원천 데이터 수집의 용이성과 데이터 발생 빈도 탐색
- 데이터 활용에 있어서 전처리 및 후처리 비용 대략 산정
- 데이터의 보안
- 수집 대상 데이터의 개인정보 포함 여부, 지적 재산권 존재 여부 판단
- 데이터 분석 시 발생할 수 있는 문제 예방
- 데이터 정확성
- 데이터 분석 목적에 맞는 적절한 데이터 항목이 존재하는지 확인
- 적절한 데이터 품질이 확보될 수 있는지 탐색
- 데이터 수집의 난이도
- 원천 데이터의 존재 위치, 데이터 유형, 데이터 수집 용량, 구축비용, 정제 과정의 복잡성을 고려하여 데이터 탐색
- 수집 비용
- 데이터를 수집하기 위해 발생할 수 있는 데이터 획득 비용 산정
- 기초 자료 등 수집
- 원천 데이터의 수집 가능성
내/외부 데이터 수집
데이터 종류
- 내부 데이터
- 서비스 시스템
- ERPㅣ, CRM, KMS, 포탈, 원장정보시스템, 인증/과금 시스템, 거래시스템 등
- 네트워크 및 서버 장비
- 백본, 방화벽, 스위치, IPS, IDS 서버 장비 로그 등
- 마케팅 데이터
- VOC 접수 데이터, 고객 포털 시스템 등
- 서비스 시스템
- 외부 데이터
- 소셜 데이터
- 제품 리뷰 커뮤니티, 게시판, 페이스북, 인스타그램 등
- 특정 기관 데이터
- 정책 데이터, 토론 사이트 등
- M2M 데이터 (사물간 통신)
- 센서 데이터, 장비 발생 로그
- LOD (웹에서 누구나 사용할 수 있도록 무료로 공개되는 연계 데이터)
- 경제, 의료, 지역 정보, 공공 정책, 과학, 교육, 기술, 산업, 역사, 환경, 과학, 통계 등 공공 데이터
- 소셜 데이터
데이터 수집 주기
- 내부 데이터 (조직 내부에서 습득할 수 있는 데이터)
- 실시간으로 수집하여 분석
- 외부 데이터
- 일괄 수집으로 끝날지, 일정 주기로 데이터를 수집할지를 결정
- 수집 데이터 관리 정책을 정해야 함
데이터 수집 방법
- 내부 데이터
- 분석에 적합한 정형화된 형식으로 수집되기 때문에 가공 용이
- 외부 데이터
- 분석 목표에 맞는 데이터 탐색, 수집, 분석 목표에 맞게 수집 데이터를 변환하는 노력 필요
| 구분 | 내부 데이터 | 외부 데이터 |
| 업무 협의 | 조직 내부의 협의에 따른 데이터 수집 | 외부 조직의 데이터 필요시 상호 협약에 의한 수집 |
| 수집 경로 | 인터페이스 생성 | 인터넷을 통한 연결 |
| 수집 대상 | 파일 시스템, DBMS, 센서 등 | 협약에 의한 DBMS 데이터, 웹 페이지, 소셜 데이터, 문서 등 |
데이터 수집 기술
데이터 유형별 데이터 수집 기술
- 수집 시스템 사양 설계를 위해 수집 데이터 유형을 파악하여 그에 맞는 수집 기술 선정
| 데이터 유형 | 데이터 수집 방식/기술 | 설명 |
| 정형 데이터 | ETL | 수집 대상 데이터를 추출 및 가공하여 데이터 웨어하우스에 저장하는 기술 |
| FTP | TCP/IP나 UDP 프로토콜을 통해 원격지 시스템으로부터 파일을 송수신하는 기술 | |
| API | 솔루션 제조사 및 3rd party SW로 제공되는 도구로, 시스템 간 연동을 통해 실시간으로 데이터를 수신할 수 있도록 기능을 제공하는 인터페이스 | |
| DBToDB | DBMS 간 데이터를 동기화 또는 전송하는 방법 | |
| Sqoop | RDBMS와 Hadoop 간 데이터를 전송하는 방법 | |
| 비정형 데이터 | 크롤링 | 인터넷상에서 제공되는 다양한 웹 사이트로부터 정보를 수집하는 기술 |
| RSS | 웹 사이트에 게시된 새로운 글을 공유하기 위해 XML 기반으로 정보를 배포하는 프로토콜 | |
| Open API | 응용 프로그램을 통해 실시간으로 데이터를 수신할 수 있도록 공개된 API | |
| 척와(Chukwa) | 분산 시스템으로부터 데이터 수집, 하둡 파일 시스템에 저장, 실시간으로 분석할 수 있는 제공 | |
| 카프카(Kafka) | 대용량 실시간 로그처리를 위한 분산 스트리밍 플랫폼 기술 | |
| 반정형 데이터 | 플럼(Flume) | 분산 환경에서 대량의 로그 데이터를 수집 전송하고 분석하는 기능 제공 |
| 스크라이브(Scribe) | 다수의 수집 대상 서버로부터 실시간으로 데이터 수집, 분산 시스템에 데이터 저장 기능 제공 | |
| 센싱(Sencing) | 센서로부터 수집 및 생성된 데이터를 네트워크를 통해 활용하여 수집하는 기능 제공 | |
| 스트리밍 (TCP, UDP, Bluetooth, RFID) |
네트워크를 통해 센서 데이터 및 오디오, 비디오 등 미디어 데이터를 실시간으로 수집하는 기술 |
* 비정형 데이터 수집 기술은 반정형 데이터에도 적용 가능
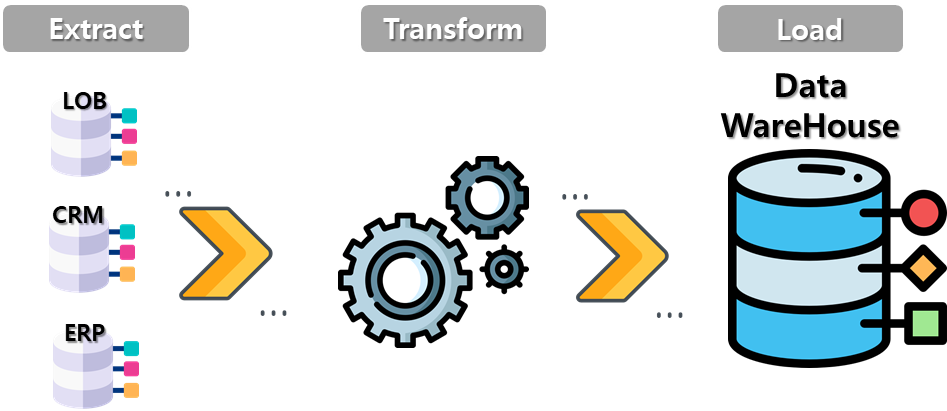
ETL(Extrac, Transform, Load)
- 하나 이상의 데이터 소스로부터 다양한 응용시스템을 위한 데이터 구축에 필요한 핵심 기술
- 데이터 웨어하우스, 데이터 마트, 데이터 통합, 데이터 이동 등
- ETL 프로세스
- 데이터 추출(Extrac)
- 하나 또는 그 이상의 데이터 원천으로부터 데이터 획득
- 데이터 변환(Transform)
- 목표로 하는 형식이나 구조로 데이터 변환
- 데이터 정제, 변환, 표준화, 통함 등 진행
- 데이터 적재(Load)
- 변환이 완료된 데이터를 특정 목표 시스템에 저장
- 데이터 추출(Extrac)
FTP(File Transfer Protocol)
- 대량의 파일(데이터)을 네트워크를 통해 주고받을 때 사용되는 파일 전송 서비스
- 서버와 클라이언트를 먼저 연결하고 이후에 데이터 파일 전송
- 서버와 클라이언트 사이에 두 개의 연결 생성(데이터 제어 연결, 데이터 전송 연결)
- 데이터 제어 연결 : 사용자 계정 및 암호 등의 정보나 파일 전송 명령 및 결과
- 데이터 전송 연결 : 파일 송수신 작업
- 데이터 제어 연결은 21번 포트, 데이터 전송 연결은 20번 포트 사용
- 인터넷을 통한 파일 송수신 만을 위해 만들어진 프로토콜
- 인터넷 프로토콜인 TCP/IP 위에서 동작
- 동작 방식이 단순하고 직관적
- 파일을 빠른 속도로 한꺼번에 송수신 가능
* TCP/IP : 서로 다른 시스템을 가진 컴퓨터들을 연결하고, 데이터를 전송하는 데 사용하는 통신 프로토콜들의 집합
정형 데이터 수집을 위한 아파치 스쿱(Sqoop) 기술
- 관계형 데이터 스토어 간 대량 데이터를 효과적으로 전송하기 위해 구현된 도구
- 커텍터를 사용하여 관계형 데이터베이스의 데이터를 하둡 파일시스템으로 수집
- 관계형 데이터베이스에서 가져온 데이터들을 하둡 맵리듀스로 변환
- 변환된 데이터들은 다시 관계형 데이터베이스로 내보내기 가능
- 데이터 가져오기/내보내기 과정을 맵리듀스를 통해 처리하기 때문에 병렬처리가 가능
| 특징 | 설명 |
| Bulk import 지원 | 전체 데이터베이스 또는 테이블을 HDFS로 전송 가능 |
| 데이터 전송 병렬화 | 시스템 사용률과 성능을 고려한 병렬 데이터 전송 |
| Direct input 제공 | RDB에 매핑하여 Hbase와 Hive에 직접적 import 제공 |
| 프로그래밍 방식의 데이터 인터랙션 |
자바 클래스 생성을 통한 데이터 상호작용 지원 |
* HDFS(Hadoop Distributed File System) : 하둡 파일 분산 시스템
* Hbasee : 하둡 플랫폼을 위한 공개 비관계형 분산 데이터베이스
* Hive : 하둡에서 동작하는 데이터 웨어하우스 인프라 구조로서 데이터 요약, 질의 및 분석 기능 제공
로그/센서 데이터 수집을 위한 아파치 플럼(Flume) 기술
- 대용량의 로그 데이터를 효과적으로 수집, 집계, 이동시키는 신뢰성 있는 분산 서비스를 제공하는 솔루션
- 스트리밍 데이터 흐름에 기반을 둔 간단하고 유연한 구조를 가짐
- 하나의 에어전트는 소스, 채널, 싱크로 구성
- 소스 : 웹서버, 로그데이터서버 등 원시데이터소스와 연결
- 채널 : 소스로부터 들어오는 데이터를 큐의 구조를 갖는 채널에 입력
- 싱크 : 목표 시스템으로 전달
- 대량의 이벤트 데이터 전송을 위해 사용
- 로그 데이터 수집과 네트워크 트래픽 데이터, 소셜 미디어 데이터, 이메일 메시지 등
| 특징 | 설명 |
| 신뢰성(Reliability) | 장애 시 로그 데이터의 유실 없이 전송 보장 |
| 확장성(Scalability) | 수평 확장을 통한 분산 수집이 가능한 구조 |
| 효율성(Efficiency) | 커스터마이징 가능, 고성능 제공 |
웹 및 소셜 데이터 수집을 위한 스크래피(Scrapy) 기술
- 웹사이트를 크롤링하고 구조화된 데이터를 수집하는 도구
- API를 이용하여 데이터를 추출할 수 있어 범용 웹크롤러로 사용
- 파이썬 기반의 프레임워크로 스크랩 과정 단순, 한 번에 여러 페이지 불러오기 용이
- 크롤링 후 바로 데이터 처리 가능
- 데이터마이닝, 정보 처리, 이력 기록 같은 다양한 애플리케이션에 유용하게 사용
참고
반응형