


반응형

# Hierarchical Clustering (=HC, 계층적 군집화)
- Unsupervised Learning
- 클러스터 계층 구조를 구축하려는 클러스터 분석 방법
- 클러스터(군집화) : 유사한 속성들을 갖는 데이터들을 그룹화 한 것
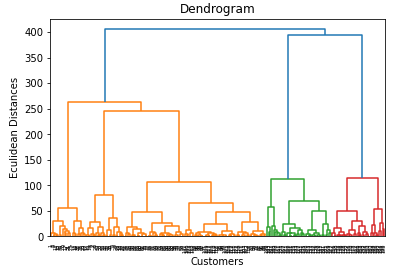
- 계층적 군집화 분석은 덴드로그램(Dendrogram) 이라는 그래프로 시각화
- 덴드로그램을 통해 적절한 수준에서 트리를 잘라 여러개의 클러스터를 나눌 수 있음
- K-Means와 달리 클러스터의 수를 사전에 정의하지 않아도 학습 수행
# Hierarchical Clustering 라이브러리 호출
import matplotlib.pyplot as plt
# 표 작성을 위한 라이브러리
import pandas
# 데이터프레임 사용을 위한 라이브러리
from sklearn.preprocessing import StandardScaler
# 피처 스케일링 표준화 사용을 위한 라이브러리
from sklearn.model_selection import train_test_split
# 인공지능 학습을 위한 라이브러리
import scipy.cluster.hierarchy as sch
# 계층적 군집화 인공지능 모델링을 위한 라이브러리
# 편의상 sch로 축약
from sklearn.metrics import confusion_matrix, accuracy_score
# 인공지능 성능을 확인하기 위한 라이브러리
# 예시에 쓰일 데이터프레임
- 수입과 소비점수를 분석하여 클러스터링(그룹화) 해보기
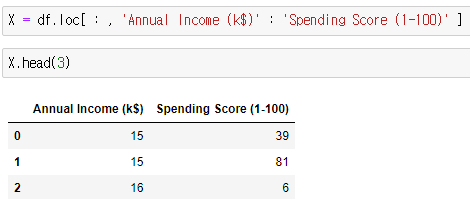
- 수입과 소비점수를 X변수에 저장

# 덴드로그램 생성하기
- sch.dendrogram( sch.linkage (데이터 , method='ward') )
- method : 클러스터 간 연결 방법
- ward : ward연결법 이용, 응집형이며 유사성이 있는 클러스터끼리 묶음
- method : 클러스터 간 연결 방법
- 덴드로그램을 통하여 최적의 클러스터 갯수 추정
- 클러스터의 갯수 판단에는 정답이 없습니다.
sch.dendrogram( sch.linkage(X, method='ward') )
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Eculidean Distances')
plt.show()
# HC 모델로 인공지능 학습하기
1. 데이터 준비
- 우선 NaN값이 존재하는지 확인, 존재하면 NaN처리

- 변수 지정, 데이터(X) 분리
- X : 수입(Annual Income (k$)) / 소비점수(Spending Score (1-100))
2. HC 모델링
- from sklearn.cluster import AgglomerativeClustering 호출
- AgglomerativeClustering : 병합적 군집 함수
- AgglomerativeClustering( n_clusters= 4)
- n_clusters : n1의 갯수만큼 그룹을 K개로 분류
- 위에서 확인한 덴드로그램을 보고 적당한 값 4로 정하여 설정
3. 인공지능 성능 테스트

반응형