


반응형

# K-Means
- Unsupervised Learning
- K개의 그룹 데이터들의 평균을 구하고 특정 그룹으로 분류 하는 것 (= Clustering)
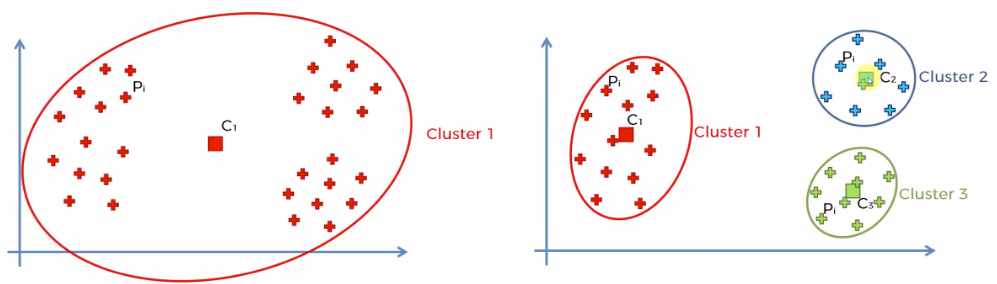
- 클러스터링 된 데이터들의 각 중심의 데이터를 구하고 최적의 K값(클러스터)을 탐색하는 것이 목표
(= Elbow Method)- 그래프가 특정 지점에서 급격히 변하여 팔꿈치 모양이 되는 곳
- X축과 거의 평행하기 시작하는 지점에 해당하는 K값을 최적 K값 혹은 최적 클러스터 값이라 함
# K-Means 라이브러리 호출
import matplotlib.pyplot as plt
# 표 작성을 위한 라이브러리
import pandas
# 데이터프레임 사용을 위한 라이브러리
from sklearn.preprocessing import StandardScaler
# 피처 스케일링 표준화 사용을 위한 라이브러리
from sklearn.model_selection import train_test_split
# 인공지능 학습을 위한 라이브러리
from sklearn.cluster import KMeans
# KMeans 인공지능 모델링을 위한 라이브러리
from sklearn.metrics import confusion_matrix, accuracy_score
# 인공지능 성능을 확인하기 위한 라이브러리
# KMeans 모델로 인공지능 학습하기
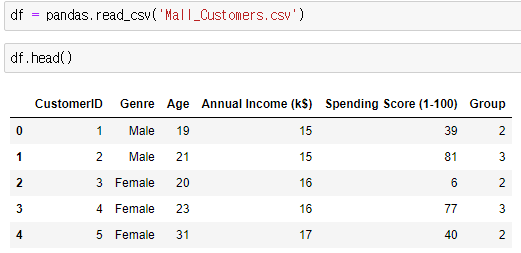
- 소득과 소비점수를 분석해서 고객별 그룹 분류
- 예시에 쓰일 데이터프레임
1. 데이터 준비
- 우선 NaN값이 존재하는지 확인, 존재하면 NaN처리

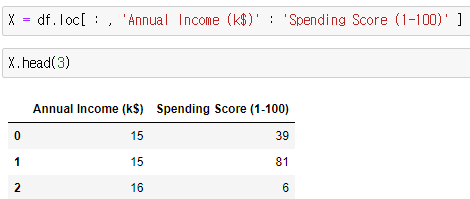
- 변수 지정, 데이터(X) 분리
- X : 수입(Annual Income (k$)) / 소비점수(Spending Score (1-100))
2. 최적의 클러스터 값 확인 및 KMeans 모델링
- from sklearn.cluster import KMeans 호출
- KMeans(n_clusters= n1 , random_state= n2 )
- n_clusters : n1의 갯수만큼 그룹을 K개로 분류
- random_state : n2의 숫자의 시드 값 사용
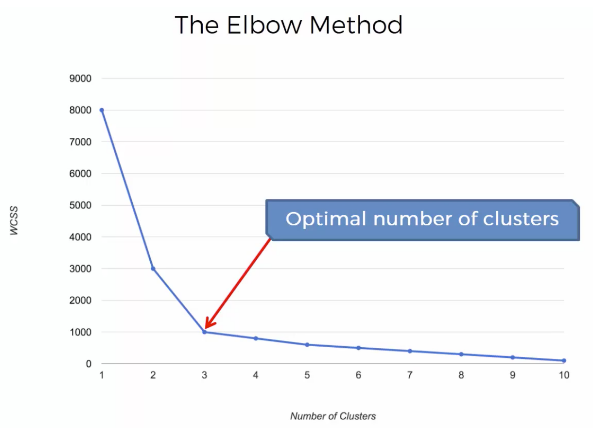
- 최적의 클러스터 값 확인하기
- 2개부터 10개까지의 클러스터를 학습시켜 클러스터별 데이터를 저장
- wcss : K개의 그룹 중심 데이터
- wcss의 값을 엘보우 메소드를 활용하여 최적의 클러스터 값 확인
- 최적의 클러스터 값에 정답은 없으니 개인 선택에 맞게 선택, 본인은 5로 선택


- 찾은 클러스터의 값을 이용하여 KMeans 모델링
- 엘보우 메소드를 보고 5가 적합하다고 생각하여 5로 설정

3. 인공지능 성능 테스트

4. 인공지능 학습 결과 시각화
plt.figure(figsize=[12,8])
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()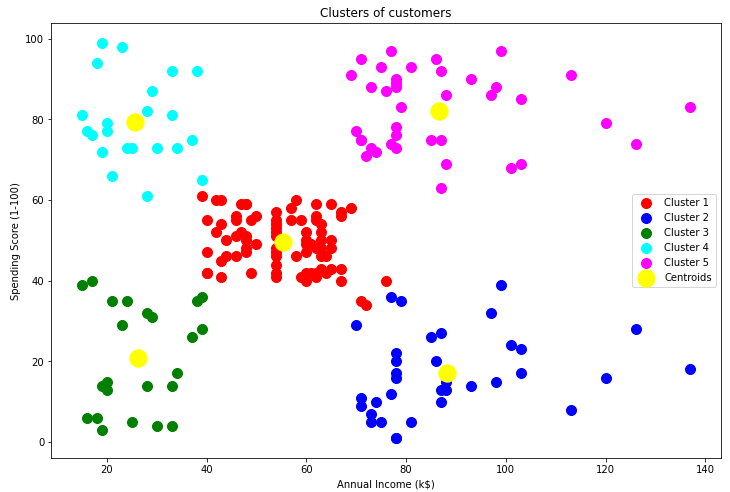
반응형