


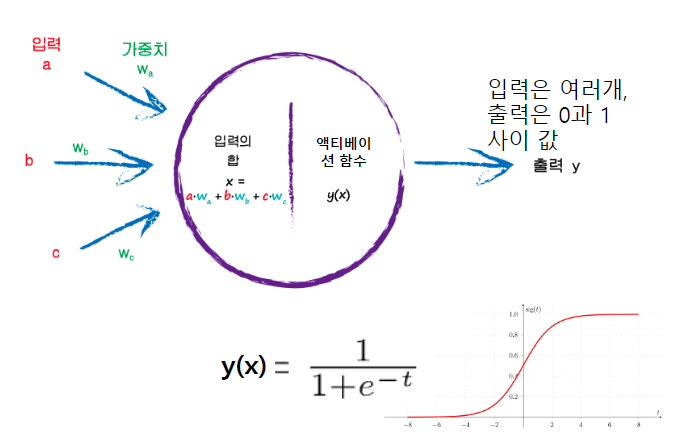
인공신경망 개요
- 인간의 두뇌 신경세포인 뉴런을 기본으로 한 기계학습 기법
- 하나의 뉴런이 다른 뉴런들과 연결되어 신호를 전달, 처리하는 구조
- 입력데이터가 들어가면서 신호의 강도에 따라 가중치 처리, 활성화함수를 통해 출력 계산
- 학습을 거쳐 원하는 결과가 나오게끔 가중치 조정
- 신경망 모델은 높은 복잡성으로 입력 자료 선택에 민감
- 신경망 모델 구축 시 고려사항
- 범주형 변수 : 일정 빈도 이상의 값으로 비슷하고 범주가 일정한 구간이어야 함
- 연속형 변수 : 입력변수 값들의 범위가 큰 차이가 없어 표준화가 가능한 경우
2022.06.09 - [Programming/Machine Learning (Python)] - 인공신경망과 딥러닝의 기초, 개념
인공신경망 발전
- 기존 신경망 다층 퍼셉트론이 가진 문제
- 사라지는 경사도(Vanishing Gradient) : 신경망 층수를 늘릴 때 데이터가 사라져 학습이 잘 되지 않는 현상
- 과대적합(Overfitting) : 데이터가 많지 않은 경우 특정 학습 데이터에만 학습이 잘되어 신규 데이터에 대한 추론처리 성능이 낮아지는 문제
- 딥러닝(Deep Learning)의 등장
- 사전학습으로 사라지는 경사도 문제 해결
- 오버피팅을 방지하는 초기화 알고리즘의 발전, 고의로 데이터를 누락시키는 드롭아웃 사용하여 해결
- 기존 인공신경망을 뛰어넘은 모델을 리브랜딩의 일환
- 기본구조인 DNN은 은닉층을 2개 이상 가진 학습 구조로 컴퓨터가 스스로 분류 답안을 만들어내며 데이터를 구분, 반복하여 최적의 답안 결정
- DNN 응용 알고리즘 모델 : CNN, RNN, LSTM, GRU, Autoencoder, GAN 등
인공싱경망 원리
- 지도 학습
- 학습 데이터로 입력벡터와 함께 기대되는 출력벡터, 즉 답을 제시
- 신경망에서 출력된 결과가 기대되는 출력과 다르면 그 차이를 줄이는 방향으로 연결 가중치 조절
- 비지도 학습
- 학습 벡터에 목표가 없을 때, 학습 데이터의 관계를 추론하여 학습을 진행하는 방식
- 입력벡터들은 집단으로 그루핑(grouping)하여 해당 집단을 대표하는 데이터 선정
- 강화 학습
- 특정 환경 안에서 에어전트가 현재 상태를 인식하여 보상을 최대화하는 방향으로 동작을 선택하는 방법

- 뉴런 간의 연결 방법
- 층간 연결 : 서로 다른 층에 존재하는 뉴런과 연결
- 층내 연결 : 동일 층 내의 뉴런과의 연결
- 순환 연결 : 어떠한 뉴런의 출력이 자기 자신에게 입력되는 연결
인공신경망 학습
- 신경망에는 적응 가능한 가중치와 편향이 존재
- 훈련 데이터에 적응하도록 조정하는 과정
- 손실 함수
- 신경망이 출력한 값과 실제 값과의 오차에 대한 함수
- 일반적인 손실함수로는 평균제곱 오차 또는 교차엔트로피 오차 활용
- 평균제곱 오차(MSE, Mean Squared Error)
- 인공신경망의 출력 값과 사용자가 원하는 출력 값 사이의 거리 차이를 오차로 사용
- 각 거리 차이를 제곱하여 합산한 후 평균을 구하는 것
- 교차엔트로피 오차(CEE, Cross Entropy Error)
- 분류 부문으로 t값이 원-핫 인코딩 벡터
- 모델의 출력 값에 자연 로그를 적용, 곱한 것
학습 알고리즘
- 1단계 : 미니배치
- 훈련 데이터 중 일부를 무작위로 선택한 데이터
- 이에 대한 손실함수를 줄이는 것으로 목표를 설정
- 2단계 : 기울기 산출
- 미니배치의 손실함수 값을 최소화하기 위해 경사법으로 가중치 매개변수의 기울기를 일반적으로 미분을 통해 구하는 것
- 3단계 : 매개변수 갱신
- 가중치 매개변수를 기울기 방향으로 조금씩 업데이트 하면서 1~3단계를 반복하는 것
- ANN을 이용하여 인공지능을 학습하는 포스팅
2022.06.10 - [Programming/Machine Learning (Python)] - Tensorflow - ANN(인공신경망) 분류 문제의 모델 딥러닝
2022.06.10 - [Programming/Machine Learning (Python)] - Tensorflow - ANN(인공신경망) 회귀 문제의 모델 딥러닝
- 인공지능 학습 시 활성함수와 손실함수를 설정하는 포스팅
2022.06.13 - [Programming/Machine Learning (Python)] - tensorflow - 분류 문제에서 활성 함수와 손실 함수 설정
오차역전파(Back Propagation)
- 가중치 매개변수 기울기를 미분을 통해 진행하는 것은 시간 소모가 큼
- 오차를 출력층에서 입력층으로 전달, 연쇄법칙을 활용한 역전파를 통해 가중치와 편향을 계산, 업데이트
- 신경망 각 계층에서의 역전파 처리
- 덧셈노드, 곱셈 노드의 연산 역전파 처리
- 활성화 함수인 렐루(Relu) 계층, 시그모이드(Sigmoid) 계층, 아핀(Affine0 계층, Softmax-with-Loss 등

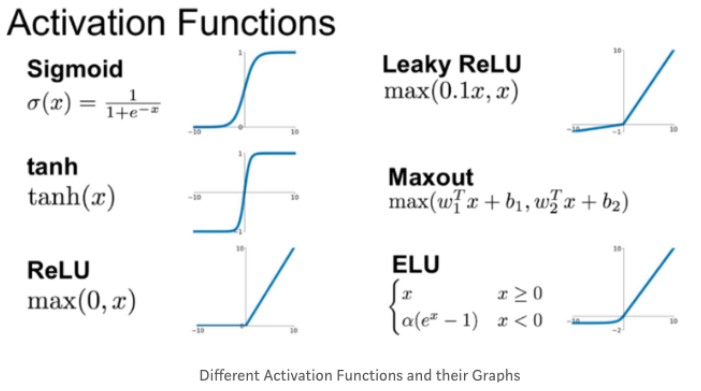
활성(활성화) 함수
- 입력 신호의 총합을 그대로 사용하지 않고 출력 신호로 변환하는 함수
- 활성화를 일으킬지를 결정
- 퍼셉트론 : 1개 이상의 입력층과 1개 출력층 뉴런으로 구성된 활성화 함수에 따라 출력
- 다중 퍼센트론 : 은닉층이 1개 이상의 퍼셉트론으로 활성화함수인 계단 함수를 사용하여 0 또는 1을 반환
- 딥러닝 인공신경망 : 시그모이드를 포함한 다른 활성화함수들을 사용, 가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습
- 시그모이드(Sigmoid) 활성화 함수 (이진 분류)
- 참에 가까워지면 0.5 ~ 1 사이의 값을 출력
- 거짓이면 0 ~ 0.5 사이의 값을 출력
- 렐루(Relu) 활성화 함수 (이진 분류)
- Sigmoid의 Gradient Vanishing 문제 해결
- 0보다 크면 입력값을 그대로 출력
- 0 이하의 값만 0으로 출력
과대적합(과적합, Overfitting)
- 기계학습에서 학습 데이터를 과하게 학습하는 것
- 학습 데이터에 대해서는 높은 정확도 성능을 보이나, 실제 데이터에 적용할 시에는 성능이 떨어지면서 오차가 증가하는 경우를 뜻함
- 해결방안
- 가중치 매개변수 절대값을 가능한 작게 만드는 가중치 감소(Weight Decay)
- 일정 비율 뉴런만 학습하는 드롭아웃(Dropout)
- 하이퍼파라미터 최적화 방법 등
- 인공지능 학습 시 드롭아웃 설정하는 포스팅
2022.06.13 - [Programming/Machine Learning (Python)] - 인공지능 - 일반화/과대적합/과소적합 개념, 과대적합 줄이기(Dropout)
- 인공지능 이용하여 하이퍼 파라미터를 찾는 포스팅
2022.05.09 - [Programming/Machine Learning (Python)] - 인공지능 머신러닝 - 최적의 인공지능 모델 찾기 (GridSearchCV)
2022.06.10 - [Programming/Machine Learning (Python)] - Tensorflow - GridSearch 최적의 하이퍼 파라미터 찾기
딥러닝 모델 종류
CNN (Convolutional Neural Network, 합성곱 신경망 모델)
개요
- 신경 네트워크(Neural Network)의 한 종류로 사람의 시신경 구조를 모방한 구조
- 인접하는 계층의 모든 뉴런과 결합된 완전 연결(전결합, fully connected)을 구현한 아핀(Affine) 계층을 사용
- 모든 입력 데이터들을 동등한 뉴런으로 처리
- 이미지 형상을 유지할 수 있는 모델
- 데이터의 특징, 차원(feature)을 추출하여 패턴을 이해하는 방식
- 이미지(벡터)의 특징을 추출하는 과정과 클래스를 분류하는 과정을 통해 진행
- 특징을 추출하는 과정은 합성곱 계층과 풀링 계층으로 분류
- 입력된 데이터를 필터가 순회하며 합성곱을 계산한 뒤 특징 지도(피처맵, Feature Map) 생성
- 특징 지도 : 서브샘플링을 통해 차원을 줄여주는 효과, 필터 크기, 스트라이드, 패딩 적용여부, 최대 풀링 크기에 따라 출력 데이터의 구조 결정
- 필터(Filter) : 이미지 특징을 찾기 위한 정사각형 행렬
- 스트라이드(Stride) : 필터는 입력 데이터를 일정한 간격인 스트라이드로 순회하면서 특징 추출, 결과로 특징지도 생성
- 패딩(Padding) : 합성곱 계층에서 필터와 스트라이드 적용으로 생성된 특징지도는 입력 데이터 크기보다 작아서 해당 출력 데이터 크기가 줄어드는 것을 사전에 방지하고자 입력 데이터 주변을 특정 값(예시로 0)을 채우는 것
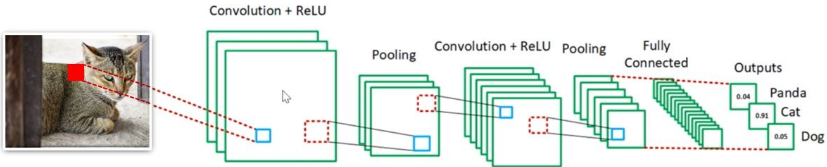
- 합성곱 연산(필터, 패딩, 스트라이드, 풀링)에 대한 내용은 이미 포스팅되어 있으므로 생략합니다.
- 합성곱 신경망(ANN)의 개념과 합성곱 연산에 대한 포스팅
2022.06.14 - [Programming/Machine Learning (Python)] - 딥러닝 - 합성곱신경망(Convolution Neural Network, CNN)
합성곱 계층(Convolution Layer)
- 2차원의 입력 데이터가 들어오면 필터의 윈도우를 일정 간격으로 이동하면서 입력 데이터에 적용
- 입력과 필터에서 대응하는 원소끼리 곱한 뒤 총합을 구하면 결과가 출력
- 모든 영역에서수행하면 합성옵의 연산 출력이 완성
- 필터의 매개변수가 완전연결 신경망의 가중치에 해당
- 학습이 반복되면서 필터의 원소값이 매번 갱신되며 편향은 항상 하나만 존재
- 3차원의 합성곱 연산에서 입력 데이터 채널 수와 필터의 채널수가 같아야 함
- 필터 크기는 임의로 설정가능하나 모든 채널의 필터 크기 동일
- 합성곱 연산에 필요 요소
- 패딩(Padding)
- 합성곱 연산을 반복수행 시 출력크기가 1이 되어 더 이상 연산을 진행하기 어려운 상태를 사전 예방하기 위한 조치로 출력크기보를 조절하는 기법
- 연산 전에 입력 데이터의 주위를 0 또는 1로 채워 출력 데이터 크기를 입력 데이터의 크기와 동일하게 설정
- 스트라이드(Stride)
- 필터를 적용하는 위치간격
- 스트라이드가 커지면 필터의 윈도우가 적용되는 간격이 넓어져 출력 데이터 크기가 줄어듦
- 패딩(Padding)
풀링 계층(Pooling Layer)
- 선택적인 요소이며 독립적인 채널별 연산
- 입력 데이터의 채널수가 변화되지 않도록 2차원 데이터의 세로 및 가로 방향의 공간을 줄이는 연산
- 최대 풀링(Max Pooling), 평균 풀링(Average Pooling) 등
- 최대 풀링 : 대상영역에서 최댓값을 취하는 연산
- 평균 폴링 : 대상 영역의 평균을 계산
- 풀링 계층을 이용하는 경우 이미지를 구성하는 요소 변경 시 출력값이 영향을 받는 문제 최소화
- 이미지 크기 축소를 통해 인공신경망의 매개변수 또한 크게 줄어들어 과적합 및 학습시간 소요 해결
평탄화 계층(Flatten Layer)
- 이미지 형태의 데이터를 배열 형태로 처리
완전연결계층(Fully Connected Layer)
- 최종 클래스 분류
CNN 구성
- 합성곱 계층 - Affine ReLU - 풀링(생략가능) 흐름으로 연결
- 출력에 가까운 층에서 Affine-ReLU 구성을 사용
- 마지막 출력 계층에서는 Affine-SoftMax 조합 이용
활용 분야
- 수치, 텍스트, 음성, 이미지들의 여러 유형의 데이터들에서 많은 특징을 자동으로 학습하여 추출, 분류, 인식 처리하는데 사용
- 대표적인 CNN 모델 : LeNet, Alexnet
- 더 깊은 층을 쌓은 CNN만 기반 심층 신경망(DNN) 모델 : VGG, GoogleLeNet, ResNet
2022.06.09 - [Programming/Machine Learning (Python)] - 딥러닝 - 심층신경망(Deep Neural Network, DNN)
RNN(Recurrent Neural Network)
- 순서를 가진 데이터를 입력하여 단위 간 연결이 시퀀스를 따라 방향성 그래프를 형성하는 신경 네트워크 모델
- 내부 상태(메모리)를 이용하여 입력 시퀀스를 처리
- CNN과 달리 중간층(은닉층)이 순환구조로 동일한 가중치 공유
- 입력 데이터의 순서(sequence)로 모두 동일 연산을 수행하며 입력 시점마다 가중치 공유
- 가중치와 편향에 대한 오차함수의 미분을 계산하기 위해 확률적 경사하강법(SDG) 이용
- 경사하강법(SDG, Stochastic Gradient Descent)
- 1차 근삿값 발견용 최적화 알고리즘
- 함수의 기울기를 구하고 경사의 반대 방향으로 계속 이동시켜 극값에 이를때까지 반복
- 오차/손실 함수(error/loss function)를 이용하여 기울기의 크기를 줄임
- 오차/손실 함수는 제곱 오차(squared error)를 이용
- 제곱 오차 : (데이터가 존재하는 목표 값 - 심층 신경망이 계산한 값)²
- 경사하강법(SDG, Stochastic Gradient Descent)
- 가중치 업데이트를 위해 과거시점까지 역전파하는 PBTT(Back Propagation Through Time) 활용
- 계산 기울기는 현재 상태와 이전 상태에 대해 의존적이므로 순차 데이터 처리에 유용

LSTM(Long Short-Term Memory Network)
- RNN은 점차 데이터가 소멸해가는 문제 발생, 학습능력이 떨어지는 문제를 보완
- 즉, RNN의 단점을 보완하기 위해 변형된 알고리즘
- 보통 신경망 대비 4배 이상 파라미터 보유하여 많은 단계를 거치더라도 오랜 시간 데이터를 기억하는 것
- 입력 게이트(Input Gate), 출력 게이트(Output Gate), 망각 게이트(Forget Gate)로 보완된 구조
- 가중치를 곱한 후 활성화 함수를 거치지 않고 컨트롤 게이트를 통해 상황에 맞게 값을 조절
- 은닉층 이외 셀이라는 층을 구성하여 해당 메모리 값이 활성화 함수를 거치고 출력 게이트를 통해 얼마나 밖으로 표현될지가 결정되면 현재의 은닉층 값이 정해짐
- 셀(C, Cell)
- 장기 메모리를 기억하는 셀
- 망각 게이트와 입력 게이트를 과거와 현재 상태의 셀로 조합
- 과거 정보를 얼마나 망각할 지 현재 정보를 얼마나 반영할지 결정
- 셀(C, Cell)
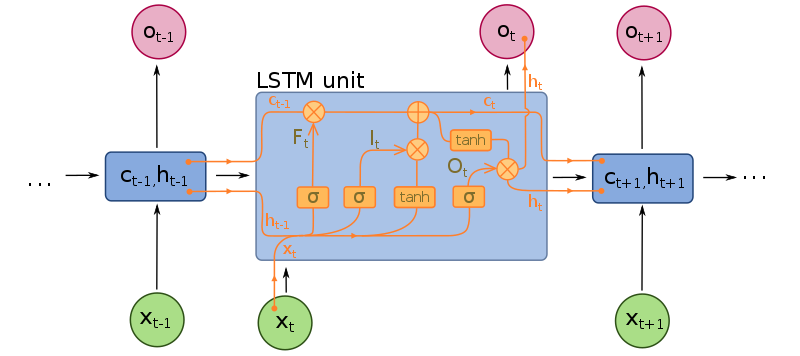
오토인코더(Auto-encoder)
- 대표적 비지도학습 모델
- 다차원 데이터를 저차원으로 바꾸고, 저차원 데이터를 다시 고차원 데이터로 바꾸면서 특징점을 찾는 것
- 입력으로 들어온 다차원 데이터를 인코더를 통해 차원을 줄이는 은닉층으로 보냄
- 은닉층의 데이터를 디코러를 통해 차원을 늘리는 출력층으로 보냄
- 출력값을 입력값과 비슷해지도록 만드는 가중치를 찾아냄
- 하나의 신경망을 두 개 붙여놓은 형태, 출력 계층과 입력 계층의 차원이 같음
| 오토인코더 세부 종류 | |
| 디노이징 오토인코더 (Denoising Auto-encoder) |
손상이 있는 입력값을 받아도 손상을 제거하고 원본의 데이터를 출력값으로 만듦 |
| 희소 오토인코더 (Sparse Auto-encoder) |
은닉층 중 매번 일부 노드만 학습하여 과적합 문제 해결 |
| VAE (Variational Auto-encoder) |
확률분포를 학습함으로써 데이터 생성 |
- 활용 분야 : 데이터 압축, 배경잡음 억제 등

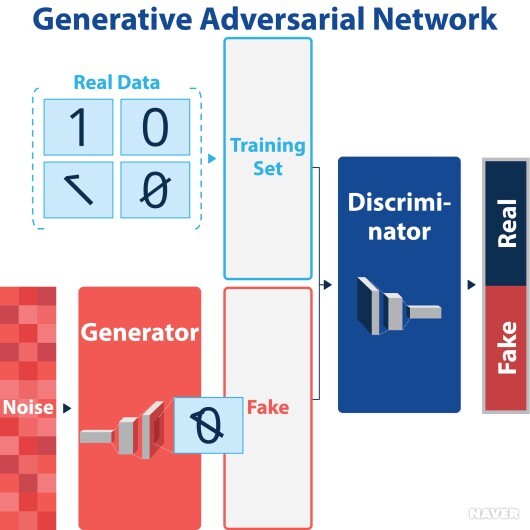
GAN(Generative Adversarial Network)
- 학습 데이터 패턴과 유사하게 만드는 생성자 네트워크와 패턴의 진위 여부를 판별하는 판별자 네트워크로 구성
- 두 네트워크가 서로의 목적을 달성하도록 학습을 반복
- 판별자 네트워크(Discriminator Network)
- 랜덤 노이즈를 m개 생성
- 생성자 네트워크에 전달
- 변환된 데이터 m개와 진짜 데이터 m개 획득
- 2m개의 데이터를 이용해 판별자 네트워크의 정확도를 최대화하는 방향으로 학습
- 생성자 네트워크(Generator Network)
- 랜덤 노이즈 m개 재생성
- 생성자가 판별자의 정확도를 최소화하는 방향으로 학습
- 판별자 네트워크(Discriminator Network)
- 생성자 네트워크에 랜덤 노이즈가 주어지며 출력은 학습 데이터와 유사한 패턴으로 변환하는 함수를 학습
- 판별자 네트워크는 생성된 데이터가 학습 데이터에 포함된 진짜인지에 대한 확률 출력
- 생성자 네트워크와 판별자 네트워크 모두 데이터 형태에 적합한 네트워크 선택
- MLP(Multi-Layer Perceptron), CNN, Autoencoder 등 제약 없이 사용 가능
- DCGAN(Deep Convolutional GAN)
- 기본적으로 두 모델간의 균형있는 경쟁이 필요
- 한쪽으로 역량이 치우치는 경우 성능의 제약을 받음
- 이를 개선한 모델
- 비지도 학습 적용을 위해 기존의 Fully Connected DNN대신 CNN기법으로 leaky_RELU 활성화 함수를 적용하여 신경망 구성
- 활용 분야 : 기초 연구, 응용 산업 등
인공신경망의 장단점
- 장점
- 비선형 예측 가능
- 다양한 데이터 유형, 새로운 학습 호나경, 불완전한 데이터 입력 등에도 적용
- 단점
- 데이터가 커질수록 학습 시간 비용이 기하급수적으로 커짐
- 모델에 대한 설명기능이 떨어지나 Explainable AI(설명가능한 AI) 등 대체안 연구
참고