자료 분석을 위한 지도 학습 모델이며, 주로 분류(SVC)와 회귀(SVR) 분석을 위해 사용
SVC : Support Vector Classification, 분류 모델
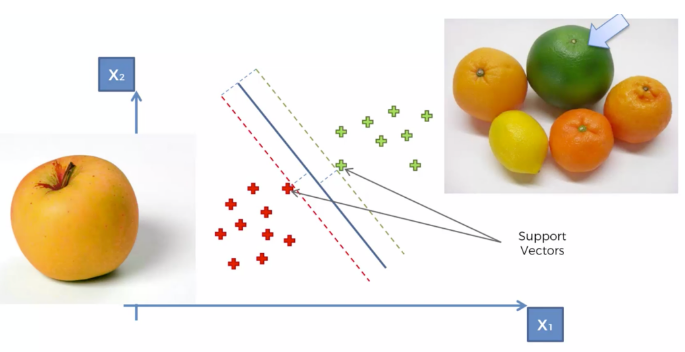
주어진 데이터 집합을 바탕으로 새로운 데이터가 어느 카테고리에 속할지 판단
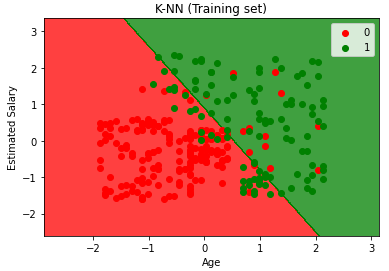
만들어진 분류 모델은 데이터가 경계로 표현, 그 중 가장 큰 폭(Margin)을 가진 경계를 찾는 것 = 즉, 마진을 최대화하는 것
마진(Margin) : 분류선(경계)에서 가장 가까운 데이터와의 거리
마진을 최대화하여 분류하기 때문에 구분하기 힘든 것까지 잘 분류하는 문제에 적합
SVR : Support Vector Regression, 회귀 모델
# SVM 라이브러리 호출
import matplotlib.pyplot as plt
# 표 작성을 위한 라이브러리
import pandas
# 데이터프레임 사용을 위한 라이브러리
from sklearn.preprocessing import StandardScaler
# 피처 스케일링 표준화 사용을 위한 라이브러리
from sklearn.model_selection import train_test_split
# 인공지능 학습을 위한 라이브러리
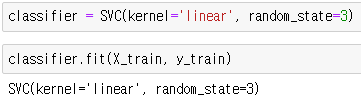
from sklearn.svm import SVC
# SVM 인공지능 모델링을 위한 라이브러리
# SVC(Support Vector Classification) 분류를 위해 사용
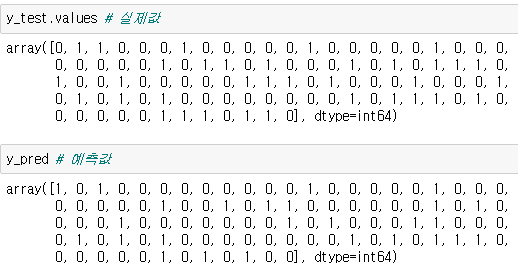
from sklearn.metrics import confusion_matrix, accuracy_score
# 인공지능 성능을 확인하기 위한 라이브러리