


글 도중 도중 해당 개념에 대한 좀 더 상세히 기재해놓은 페이지도 같이 포함해두었습니다.
인공지능(AI, Artificial Intelligence)
인공지능의 정의
- 기계를 지능화하는 노력
- 지능화란 객체가 환경에서 적절히 예지력을 갖고 작동하도록 하는 것
- 합리적 행동 수행자
- 어떤 행동이 최적의 결과를 낳을 수 있도록 하는 의사결정 능력을 갖춘 에어전트를 구축하는 것
- 설정한 목표를 극대화하는 행동을 제시하는 의사결정 로직
인공지능, 기계학습, 딥러닝의 관계
- 인공지능을 논할 때 기계학습과 딥러닝을 혼재하여 사용
- 인공지능
- 사람이 생각하고 판단하는 사고 구조를 구축하려는 전반적인 노력
- 기계학습
- 인공지능의 연구 분야 중 하나
- 인간의 학습 능력과 같은 기능을 축적된 데이터를 활용하여 실현하고자 하는 기술 및 방법
- 딥러닝
- 기계학습 방법 중 하나
- 컴퓨터가 많은 데이터를 이용해 사람처럼 스스로 학습할 수 있도록 인공신경망 등의 기술을 이용한 기법
딥러닝(Deep Learning)의 특징
2022.06.09 - [Programming/Machine Learning (Python)] - 인공신경망과 딥러닝의 기초, 개념
- 전신인 신경망(Neural Network)의 여러 단점을 극복해 유연성과 확장성을 확보
- 함수추정 방법으로써의 신경망 관점에서 정보를 압축, 가공, 재현하는 알고리즘으로 일반화
- 깊은 구조에 의해 엄청난 양의 데이터를 학습
기계학습(Machine Learning)의 종류
2022.05.31 - [Programming/Machine Learning (Python)] - 인공지능 머신러닝의 기초, 개념, 종류
- 지도학습(Supervised Learning)
- 학습 데이터로부터 하나의 함수를 유추해내기 위한 방법
- 훈련 데이터로부터 주어진 데이터에 대해 예측하고자 하는 값을 올바로 추측해 내는 것
- 비지도학습(Unsupervised Learning, =자율학습)
- 학습 데이터 없이 데이터가 어떻게 구성되었는지를 알아내는 문제의 범주를 확인하는 방법
- 지도학습 혹은 강화학습과는 달리 입력값에 대한 주어진 목표치 미존재
- 통계의 밀도 추정(Density Estimation)과 깊은 연관성을 가지며 데이터의 중요 특징을 요약하고 설명
- 준지도학습(Semi-supervised Learning)
- 목표값이 표시된 데이터와 표시되지 않은 데이터를 모두 학습에 사용하는 것
- 목표값이 없는 데이터에 적은 양의 목표값을 포함한 데이터를 사용할 경우 학습 정확도 상승
- 강화학습(Reinforcement Learning)
- 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 순서를 선택하는 방법
- 학습 과정에서의 성능을 초점으로 두고 탐색과 이용의 균형을 맞춰 최상의 전략을 학습
기계학습 방법에 따른 인공지능 응용분야
- 지도학습
- 분류모형(Classification) : 훈련 데이터로 훈련되어야하며 어떻게 분류할지 학습하는 것
- 이미지 인식
- 음성 인식
- 신용평가 및 사기검출
- 불량예측 및 원인발굴
- 회귀모형(Regression) : 예측 변수라 부르는 특성을 사용해 목표 수치를 예측 하는 것
- 시세/가격/주가 예측
- 강우량 예측
- 분류모형(Classification) : 훈련 데이터로 훈련되어야하며 어떻게 분류할지 학습하는 것
- 비지도학습
- 군집분석(Clustering) : 각 그룹을 더 작은 그룹으로 세분화하는 것
- 텍스트 토픽 분석
- 고객 세그멘테이션(고객 세분화)
- 오토인코더(AutoEncoder) : 인코더를 통해 입력을 신호로 변환한 다음 다시 디코더를 통해 레이블 따위를 만들어내는 것
- 이상징후 탐지
- 노이즈 제거
- 텍스트 벡터화
- 생성적 적대 신경망(Generative Adversarial Network) : 임의의 랜덤 노이즈로부터 가상의 데이터를 생성하는 네트워크가 실제와 같은 데이터를 생성 할 수 있도록 진위 여부를 판별할 수 있는 네트워크를 붙여 경쟁적으로 학습시키는 것
- 시뮬레이션 데이터 생성
- 이미지 생성 (예:딥페이크)
- 누락 데이터 생성
- 패션 데이터 생성
- 시뮬레이션 데이터 생성
- 군집분석(Clustering) : 각 그룹을 더 작은 그룹으로 세분화하는 것
- 강화 학습
- 강화 학습 : 환경을 관찰해서 행동을 실행하고 그 결과로 가장 큰 보상을 얻기 위해 최상의 전략을 스스로 학습하는 것
- 게임 플레이어 생성(예: 알파고)
- 로봇 학습 알고리즘
- 공급망 최적화
- 강화 학습 : 환경을 관찰해서 행동을 실행하고 그 결과로 가장 큰 보상을 얻기 위해 최상의 전략을 스스로 학습하는 것
인공지능 데이터 학습의 진화
전이학습 (Transfer Learning)
- 인간의 응용력과 같이 유사 분야에 학습된 딥러닝 모형을 다른 문제를 해결하기 위해 사용하고자 하는 학습 방법
- 하나의 문제를 해결하고 새로운 유사한 문제에 적용하면서 얻은 지식을 저장하는데 초점을 맞춘 것
- 적은 양의 데이터로도 좋은 결과를 도출 할 수 있음
- 주로 이미지, 언어, 텍스트 인식과 같이 지도학습 중 분류 모형인 인식(recognition) 문제에 활용 가능
- 인식 문제의 경우 데이터 표준화가 가능하여 사전학습모형 입력형식에 맞출 수 있음
+ 레코그니션(Rekognition) 파이썬 구현
2022.06.24 - [Programming/Rest API (Python)] - API서버 - Rekognition 객체 탐지 API 구현하기
전이학습 기반 사전학습모형(Pre-trained Model)
- 학습 데이터에 의한 인지능력을 갖춘 딥러닝 모형에 추가적인 데이터를 학습시키는 방식
- 데이터 학습량에 따라 점차 발전하는 것도 중요하지만 응용력을 갖추는 것을 필수로 함
- 상대적으로 적은 양의 데이터로도 제한된 문제에 인공지능 적용 가능
- 이미 학습된 사전학습모형도 데이터를 함축한 초보적 인공지능으로 충분한 가치를 지닌 새로운 의미의 데이터라고 할 수 있음
BERT(Bidirectional Encoder Representations form Transformers)
- 언어 인식 사전학습 모형
- 확보된 언어 데이터의 추가 학습을 통한 신속한 학습 가능
- 다층의 임베딩 구조를 통해 1억 2천개가 넘는 파라미터로 구성된 획기적인 모형
- 임베딩(Embedding) : 특정 데이터를 숫자로 채워진 벡터, 행렬로 바꾸는 과정
- 256개까지의 문자가 입력되어 768차원 숫자 벡터가 생성되는 방식
- 언어 인식 뿐 아니라 번역, 챗봇의 Q&A 엔진으로 활용 가능
+ AI 챗봇 구현
빅데이터와 인공지능의 관계
인공지능을 위한 학습 데이터 확보
- 학습 데이터 측면을 고려한 양질의 데이터 확보는 결국 성공적인 인공지능 구현과 직결
- 딥러닝은 깊은 구조를 통해 무한한 모수 추정이 필요한 만큼 많은 양의 데이터 필요
- 인공지능 학습에 활용될 수 있는 데이터로 가공 필요
- 학습의 가이드를 제공해주는 애노테이션 작업 필수
학습 데이터의 애노테이션 작업
애노테이션(Annotation) : 데이터상의 주석 작업으로 딥러닝과 같은 학습 알고리즘이 무엇을 학습하여야하는지 알려주는 표식 작업
- 많은 데이터 확보 후 애노테이션을 통해 학습이 가능한 데이터로 가공
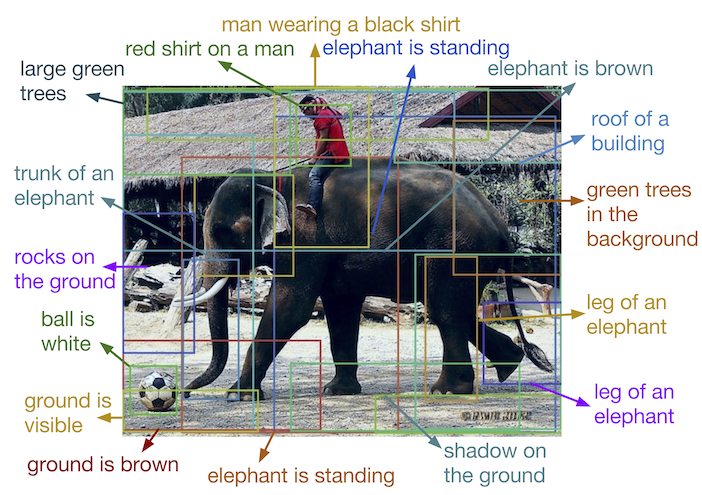
애노테이션 작업을 위한 도구로써의 인공지능
- 인공지능 시장이 확장되며 애노테이션 작업을 전문으로 하는 기업의 수 증가
- 경쟁으로 인해 학습용 데이터에 대한 보안 및 애노테이션 결과에 대한 품질 요구수준 상승
- 기업들은 데이터 업로드 및 애노테이션 도구, 작업 모니터링을 위한 플랫폼 제공
- 현재 자동으로 애노테이션을 수행해주는 인공지능 기반의 애노테이션 도구를 제공하는 서비스로 진화 중
인공지능의 기술동향
기계학습 프레임워크 보급 확대
기계학습 프레임워크(Machine Learning Framework) : 인터페이스와 라이브러리, 툴 등 기계학습 모형 개발을 쉽고 빠르게 하도록 지원하는 기반
- 텐서플로우(Tensorflow)는 파이썬 기반 딥러닝 라이브러리로 여러 CPU 및 GPU 플랫폼에서 사용 가능
- 케라스(Keras)는 파이썬 기반 딥러닝 신경망 구축을 위한 단순화된 인터페이스를 가진 라이브러리로 몇 줄의 코드만으로 딥러닝 모형 개발 가능
+ 텐서플로우, 케라스 사용 간단 예시
2022.06.10 - [Programming/Machine Learning (Python)] - 딥러닝 - 텐서플로우의 기초, 개념, 간단 예시
생성적 적대 신경망(GAN)
- 생성적 적대 신경망(GAN, Generative Adversarial Networks)을 보통 GAN이라고 칭함
- GAN은 두 개의 인공신경망으로 구성된 딥러닝 이미지 생성 알고리즘
- 생성자가 가짜 사례를 생성하면 감별자가 진위를 판별하도록 구성한 후 이들이 적대적 관계 속에서 공방전 반복하는 것
- 가짜 사례의 정밀도를 점점 더 진짜 사례와 구별하기 어려운 수준으로 높이는 방식으로 작동
- 주로 새로운 합성 이미지를 생성하는 분석에 많이 적용, 점차 다른 분야에 응용하는 사례 증가
오토인코더
오토인코더(Auto-encoder) : 라벨이 설정되어 있지 않은 학습 데이터로부터 더욱 효율적인 코드로 표현하도록 학습하는 신경망
- 입력 데이터의 차원을 줄여 모형을 단순화 시키기 위해 활용
설명 가능한 인공지능(XAI)
설명 가능 인공지능(XAI, eXplainable AI) : 판단에 대한 이유를 사람이 이해할 수 있는 방식으로 제시하는 인공지능
- 결론 도출 과정에 대한 근거를 차트나 수치 또는 자연어 형태의 설명으로 제공
- 불확실성을 해소하여 인공지능에 대한 신뢰성 상승
- 블랙박스 인공지능과 대비되는 개념
블랙박스 : 특정한 판단에 대해 알고리즘의 설계자조차도 그 이유를 설명할 수 없는 것
블랙박스 인공지능 : 기존의 기계학습의 완성된 모형은 내부 구조가 매우 복잡하고 의미를 이해하기 난해
기계학습 자동화(AutoML)
- 기계학습의 전체 과정을 자동화하는 것
- 세부적으로는 데이터 전처리, 변수 생성, 변수 선택, 알고리즘 선택, 하이퍼파라미터 최적화 등의 기능 수행
- 기계학습 모형 개발 과정의 생산성을 높이며 비전문가들의 활용 용이
+ 데이터 전처리
+ 하이퍼파라미터 최적화
2022.05.09 - [Programming/Machine Learning (Python)] - 인공지능 머신러닝 - 최적의 인공지능 모델 찾기 (GridSearchCV)
2022.06.10 - [Programming/Machine Learning (Python)] - Tensorflow - GridSearch 최적의 하이퍼 파라미터 찾기
인공지능의 한계점과 발전방향
국내시장의 한계
- 국내에서 축적한 머신러닝 및 인공지능과 관련한 수학, 통계학적의 낮은 이해도
- 인공지능 개발을 위한 데이터 확보 및 중요성에 대한 인식 부족
인공지능의 미래
- 딥러닝의 재학습 및 전이학습 특성을 활용한 사전학습모형을 새로운 데이터 경제로 예상
- 마스킹이나 라벨링 등의 애노테이션 작업을 통해 학습용 데이터를 가공하는 산업 확산
- 복잡한 BERT의 학습을 위한 구글의 클라우드 서비스와 같은 확장된 개념의 데이터 경제 파생 예상
- 수집 : 데이터 경제
- 가공 : 학습용 데이터로
- 구분 : 전이학습용 사전학습 모형