


빅데이터 처리과정과 요소기술

데이터 (생성)
- 데이터베이스나 파일 관리 시스템과 같은 내부 데이터 존재
- 인터넷으로 연결도니 외부로부터 생성된 파일이나 데이터 존재
수집
- 크롤링을 통해 데이터 원천으로부터 데이터 검색하여 수집
- 크롤링(Crawling) : 웹사이트 등 외부에 저장되어 있는 정보자원을 자동화된 방법으로 수집, 분류, 저장하는 것
- ETL(추출, 정제, 가공)을 통해 소스 데이터로부터 추출, 변환, 적재
- 단순한 수집이 아니라 검색 및 수집, 변환 과정 모두 포함
- 로그 수집기나 센서 네트워크 및 Open API 등 활용
저장 (공유)
- 저렴한 비용으로 데이터를 쉽고 빠르게 많이 저장
- 정형 데이터뿐만 아니라 반정형, 비정형 데이터도 포함
- 벙렬 DBMS나 하둡(Hadoop), NoSQL 등 다양한 기술 사용
- 시스템 간의 데이터 서로 공유
처리
- 데이터를 효과적으로 처리하는 기술이 필요한 단계
- 분산 병렬 및 인메모리 방식으로 실시간 처리
- 인메모리(In-memory) : 디스크가 아닌 메인 메모리에 데이터를 저장하는 기술
- 대표적으로 하둡(Hadoop)의 맵리듀스(MapReduce) 활용
분석
- 데이터를 신속하고 정확하게 분석하여 비즈니스에 기여
- 특정 분야 및 목적의 특성에 맞는 분석 기법 선택 중요
- 통계분석, 데이터 마이닝, 텍스트 마이닝, 기계학습 방법 등
시각화
- 처리 및 분석 결과를 표, 그래프등을 이용해 쉽게 표현하고 탐색이나 해석에 활용
- 정보 시각화 기술, 시각화 도구, 편집 기술, 실시간 자료 시각화 기술로 구성
빅데이터 수집
- 크롤링(Crawling) : 무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술
- 로그 수집기 : 조직 내부에 있는 웹 서버나 시스템 로그를 수집하는 소프트웨어
- 센서 네트워크(Sensor Network) : 유비쿼터스 컴퓨팅 구현을 위한 초경량 저전력의 많은 센서들로 구성된 유무선 네트워크
- RSS Reader/Open API : 데이터의 생산, 공유, 참여할 수 있는 환경인 웹2.0 구현 기술
- ETL 프로세스 : 데이터의 추출(Extract), 변환(Transform), 적재(Load)의 약어로, 다양한 원천 데이터를 취합해 추출하고 공통된 형식으로 변환하여 적재하는 과정
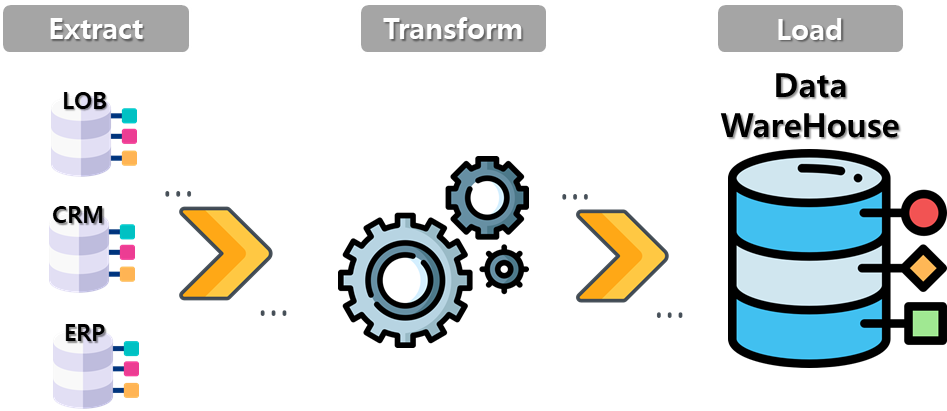
| 과정 | 설명 |
| 데이터 추츨 (Extract) | - 원천 데이터로부터 적재하고자 하는 데이터 추출 |
| 데이터 변환 (Transform) | - 추출한 데이터를 변환하고 균질화하며 정제 - 정제한 데이터를 적재하고자 하는 데이터 웨어하우스 구조에 맞게 변환 - 통합하는 제약 조건 및 비즈니스 규칙에 따라 필터링이나 확인 작업 진행 |
| 데이터 적재 (Load) | - 변환된 데이터를 데이터 웨어하우스에 적재 |
빅데이터 저장
NoSQL(Not-only SQL)
- 전통적인 관계형 데이터베이스와는 다르게 데이터 모델을 단순화하여 설계된 비관계형 데이터베이스
- SQL을 사용하지 않는 DBMS와 데이터 저장장치
- 기존의 RDBMS 트랜잭션 속성 포기
- 원자성(Atomicity), 일관성(Consistency), 독립성(Isolation), 지속성(Durability)
- 데이터 업데이트가 즉각적으로 가능한 데이터 저장소
- 대표적으로 Cloudata, Hbase, Cassandra, MongoDB
공유 데이터 시스템(Shared-data System)
- 일관성(Consistency), 가용성(Availability), 분할 내성(Partition Tolerance) 중 최대 두 개의 속성만 보유 가능
- CAP 이론 : 분산 데이터베이스 시스템의 이론
- 분할 내성을 취하고 일관성과 가용성 중 하나를 포기
- 일관성과 가용성을 모두 취하는 기존 RDBMS보다 높은 성능과 확장성 제공
병렬 데이터베이스 관리 시스템(Parallel Database Management System)
- 다수의 마이크로프로세서를 사용하여 여러 디스크에 질의, 갱신, 입출력 등 데이터베이스 처리를 동시에 수행하는 시스템
- 확장성 제공을 위해 작은 단위의 동작으로 트랜잭션 적용 필요
- 대표적으로 BoltDB, SAP HANA, Vertica, Greenplum, Netezza
분산 파일 시스템
- 네트워크로 공유하는 여러 호스트의 파일에 접근할 수 있는 파일 시스템
- 데이터를 분산하여 저장하면 데이터 추출 및 가공 시 빠르게 처리 가능
- 대표적으로 GFS(Google File System), HDFS(Hadoop Distributed File System), 아마존 S3 파일 시스템
네트워크 저장 시스템
- 이기종 데이터 저장 장치를 하나의 데이터 서버에 연결하여 총괄적으로 데이터를 저장 및 관리하는 시스템
- 이기종 데이터 : 하나 이상의 데이터 저장 장치를 사용하는 것
- 대표적으로 SAN(Storage Area Network), NAS(Network Attached Storage)
- SAN : 원격 컴퓨터 기억 장치를 서버에 부착하는 구조
- NAS : 컴퓨터를 직접 연결하지 않고 근거리 통신 네트워크를 통해 데이터를 주고 받는 구조
빅데이터 처리
- 분산 시스템과 병렬 시스템이 존재하나 서로 중첩되는 부분이 많아 실제 시스템에서도 이 둘을 명확히 구분하지 않음
- 두 개념을 아우르는 '분산 병렬 컴퓨팅'이라는 용어 사용
분산 시스템과 병렬 시스템
- 분산 시스템
- 네트워크상에 분산되어 있는 컴퓨터를 단일 시스템인 것처럼 구동하는 기술
- 노드는 각각의 독립된 시스템을 가짐
- 독립 컴퓨터의 집합으로 만들었으나 마치 단일 시스템인 것처럼 수행
- 병렬 시스템
- 문제 해결을 위해 CPU 등의 자원을 데이터 버스나 지역 통신 시스템 등으로 연결하여 구동하는 기술
- 분할된 작업을 동시에 처리하여 계산 속도 증진
분산 병렬 컴퓨팅
- 다수의 독립된 컴퓨팅 자원을 네트워크상에 연결하여 이를 제거하는 미들웨어를 이용해 하나의 시스템으로 동작하게 하는 기술
- 미들웨어(Middleware) : 하드웨어나 프로토콜, 통신환경 등을 연결하여 응용 프로그램 간 원만한 통신이 이루어질 수 있게 하는 소프트웨어
| 문제 | 설명 |
| 전체 작업의 배분 문제 | - 전체 작업을 잘 쪼개어 여러 개의 작은 작업으로 배분 |
| 각 프로세서에서 계산된 중간 결과물을 프로세서 간 주고받는 문제 | - 효율적인 통신은 성능과 직결 - 보통 단일 시스템은 전체 작업을 노드 수만큼 균등하게 배분 - 이종 시스템은 컴퓨팅 능력에 따라 전체 작업을 배분 - 노드 간 통신을 최소화하는 기법 등이 반영되면 자원을 좀 더 효율적으로 사용할 수 있어 성능 향상에 기여 |
| 서로 다른 프로세서 간 동기화 문제 | - 데이터 병렬 처리에서 동기적 방법을 사용할 경우 프로세서는 특정 계산이 끝나거나 특정 데이터를 넘겨받을 때까지 반드기 대기 - 동기적 방법의 경우 송신자는 수신자에게 데이터를 받았다는 응답이 올 때까지 대기 - 비동기적 방법의 경우 결과 메시지를 보낸 즉시 다음 작업 진행, 기다릴 필요는 없지만 계산 과정이 적합한지 확인 필요 |
하둡(Hadoop)
- 분산 처리 환경에서 대용량 데이터 처리 및 분석을 지원하는 오픈 소스 소프트웨어 프레임워크
- 분산파일시스템(HDFS), 분산컬럼기반 데이터베이스(Hbase), 분산 컴퓨팅 지원 프레임워크(MapReduce)로 구성
- 분산파일시스템을 통해 수 천대의 장비에 대용량 파일을 나누어 저장하는 기능 제공
- 분산파일시스템에 저장된 대용량의 데이터들을 맵리듀스를 이용하여 실시간 처리 및 분석
- 하둡의 부족한 기능을 보완하는 하둡 에코시스템 등장으로 다양한 솔루션 제공
아파치 스파크(Apache Spark)
- 실시간 분산형 컴퓨팅 플랫폼
- In-Memory 방식으로 처리
- 인메모리(In-memory) : 디스크가 아닌 메인 메모리에 데이터를 저장하는 기술
- 하둡보다 처리속도가 빠름
- 스칼라 언어로 개발되었지만 Java, R, Python 지원
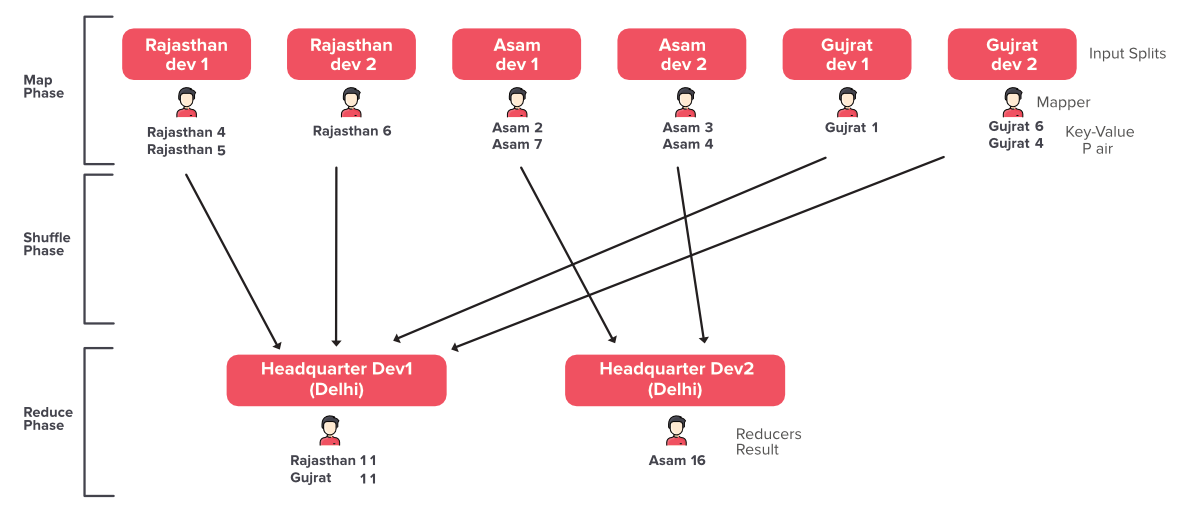
맵리듀스(MapReduce)
- 분산 병렬 데이터 처리 기술의 표준
- 방대한 양의 데이터를 신속하게 처리하는 프로그래밍 모델로 효과적인 병렬 및 분산 처리 지원
- 런타임에서의 입력 데이터 분할, 작업 스케줄링, 노드 고장, 노드 간 데이터 전송 작업이 맵리듀스 처리 성능에 많은 영향을 받음
| 맵리듀스 처리단계 | |
| 1단계 | 입력 데이터를 읽고 분할 |
| 2단계 | 분할된 데이터를 할당해 맵 작업 수행 후, 결과인 중간 데이터를 통합 및 재분할 |
| 3단계 | 통합 및 재분할된 중간 데이터 셔플(Shuffle) |
| 4단계 | 셔플된 중간 데이터로 리듀스 작업 수행 |
| 5단계 | 출력 데이터 생성 후 맵리듀스 처리 종료 |
빅데이터 분석
데이터 분석 방법의 분류
- 탐구 요인 분석(EFA, Exploratory Factor Analysis)
- 데이터 간 상호 관계를 파악하여 데이터를 분석하는 방법
- 확인 요인 분석(CFA, Confirmatory Factor Analysis)
- 관찰된 변수들의 집합 요소 구조를 파악하기 위한 통계적 기법을 통해 데이터를 분석하는 방법
데이터 분석 방법
- 분류 (Classification)
- 미리 알려진 클래스들로 구분되는 학습 데이터셋을 학습시켜 새로 추가되는 데이터가 속할 만한 데이터셋을 찾는 방법
- 학습 데이터셋을 이용하는 지도학습 방법
- 군집화 (Clustering)
- 특성이 비슷한 데이터를 하나의 그룹으로 분류하는 방법
- 분류와 달리 학습 데이터셋을 이용하지 않는 비지도학습 방법
- 기계학습 (Machine Learning)
- 인공지능 분야에서 인간의 학습을 모델링한 방법
- 다양한 학습 방법 존재
- 의사결정트리 등 기호적 학습
- 신경망이나 유전 알고리즘 등 비기호적 학습
- 베이지안이나 은닉 마코프 등 확률적 학습 등
* 마이닝 (Mining) : 데이터로부터 통계적인 의미가 있는 개념이나 특성을 추출하고 패턴이나 추세 등의 정보를 끌어내는 과정
- 텍스트 마이닝 (Text Mining)
- 자연어 처리 기술 이용
- 인간의 언어로 쓰인 비정형 텍스트에서 유용한 정보를 추출하거나 다른 데이터와의 연관성을 파악하기 위한 방법
- 분류나 군집화 등 빅데이터에 숨겨진 의미 있는 정보를 발견하는데 사용
- 웹 마이닝 (Web Mining)
- 인터넷을 통해 수집한 정보를 데이터 마이닝 방법으로 분석하는 응용분야
- 오피니언 마이닝 (Opinion Mining)
- 온라인의 다양한 뉴스와 소셜 미디어 코멘트 또는 사용자가 만든 콘텐츠에서 표현된 의견을 추출, 분류, 이해하는 응용분야
- 리얼리티 마이닝 (Reality Mining)
- 휴대폰 등 기기를 사용
- 인간관계와 행동 양태 등을 추론하는 응용분야
- 통화량, 통화 위치, 통화 상태, 통화 대상, 통화 내용 등을 분석하여 사용자의 인간관계나 행동 특성 도출
- 소셜 네트워크 분석 (Social Network Analysis)
- 수학의 그래프 이론을 바탕
- SNS에서 네트워크 연결 구조와 강도를 분석하여 사용자의 명성 및 영향력을 측정하는 방법
- 감성 분석 (Sentiment Analysis)
- 문장의 의미를 파악하여 글의 내용에 긍정 또는 부정을 분류하고 강도를 지수화하는 방법
- 도출된 지수를 이용하여 고객의 감성 트렌드를 시계열로 분석하고 고객의 감성 변화에 기업들이 신속하게 대응 및 부정적인 의견의 확산을 방지하는데 활용
참고