


반응형
과대적합 방지
* 과대적합 : 훈련 시에는 높은 성능을 보이지만 테스트 데이터에 대해서는 낮은 성능을 보이는 현상
모델의 낮은 복잡도
- 훈련데이터를 더 많이 획득할 수 없다면 정규화, 드롭아웃 등을 활용하여 적절한 복잡도를 가진 모델을 자동으로 탐색
하이퍼파라미터(Hyper Parameter)
- 과대적합의 위험을 줄이기 위해 제약을 가하는 규제의 양을 결정하는 인수
- 상수값인 하이퍼파라미터(학습률, 각층의 뉴런수 등)의 값이 클수록 복잡도 저하
드롭아웃(Dropout)
- 신경망 모델에서 은닉층의 뉴런을 임의로 삭제하면서 학습하는 방법
- 훈련 시
- 삭제할 뉴런을 선택
- 테스트 시
- 모든 뉴런에 신호 전달
- 각 뉴련의 출력에 훈련 때 삭제한 비율을 곱하여 전달
- 단점
- 적은 수의 뉴런들로 학습 시 시간 오래 소요
가중치 감소(Weight Decay)
- 학습과정에서 큰 가중치에 대해서는 큰 패널티를 부과하여 가중치의 절대값을 가능한 작게 만드는 것
- 규제를 이용하여 과대적합이 되지 않도록 모델을 강제로 제한
- 과적합을 방지하기 위해 회귀계수 w가 커지지 않도록 하는 방법
L2 규제(L2 Regularization)

- 손실함수에 가중치에 대한 L2 노름(norm)의 제곱을 더한 패널티를 부여하여 가중치 값을 비용함수 모델에 비해 작게 생성
- norm : 벡터의 크기(길이)를 측정하는 방법(또는 함수)
- 손실함수가 최소가 되는 가중치 값인 중심점을 찾아 큰 가중치를 제한, 람다로 규제의 강도를 크게 하면 가중치는 0에 근접
- 회귀 모델에서 L2 규제를 적용한 모델 : 릿지(Ridge)

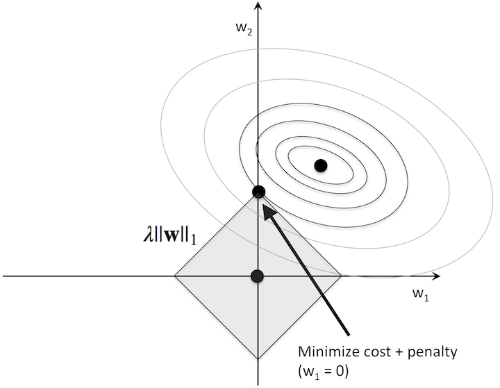
L1 규제(L1 Regularization)
- L2 규제의 가중치 제곱을 절대값으로 바꾸는 개념
- 손실함수에 가중치의 절대값인 L1 노름(norm)을 추가 적용하여 희소한 특성 벡터가 되어 대부분의 특성 가중치를 0으로 만듬
- 회귀 모델에서 L1규제를 적용한 모델 : 라쏘(Lasso)
편향-분산 트레이드오프
- 과대적합과 과소적합 사이의 적절한 편향-분산 트레이드 오프, 절중점을 찾음
- 모든 형태의 지도 학습에 응용
참고
반응형