


반응형
지도학습 - 분류 모델 평가 지표
- 분석 모델의 답과 실제 답과의 관계 오차행렬을 통해 평가
오차행렬(혼동행렬, Confusion Matrix)
- 훈련을 통한 예측 성능을 측정하기 위해 예측 값과 실제 값을 비교하기 위한 표

- True Positive(TP) : 실제 True인 답을 True라고 예측(정답)
- False Positive(FP) : 실제 False인 답을 True라고 예측(오답)
- False Negative(FN) : 실제 True인 답을 False라고 예측(오답)
- True Negative(TN) : 실제 False인 답을 False라고 예측(정답)
- 정확도(Accuracy) : 실제 데이터와 예측 데이터를 비교하여 같은 지 판단

- 정밀도(Precision) : Positive로 예측한 대상 중 실제와 예측 값이 일치하는 비율
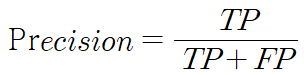
- 재현율(Recall) : 실제 Positive인 대상 중 실제와 예측 값이 일치하는 비율
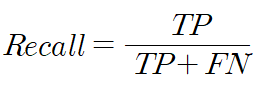
- F1 Score : 정밀도와 재현율을 결합한 조화평균 지표로 값이 클수록 모델이 정확하다고 판단
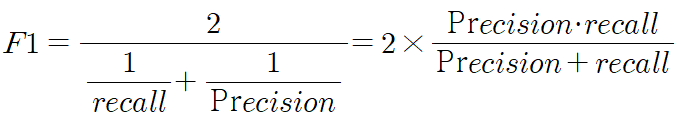
- ROC(Receiver Operating Characteristic) 곡선
- FPR(False Positive Rate)이 변할 때 민감도인 TPR(True Positive Rate)이 어떻게 변화하는지를 나타내는 곡선
- 임계값을 1~0 범주 이내 값으로 조정하면서 FPR에 따른 TPR을 계산하면서 곡선을 그림
- TPR 값과 FPR 값이 0.5인 기본 모델 위에 ROC가 위치할 경우 성능이 기본 모델보다 나음을 의미
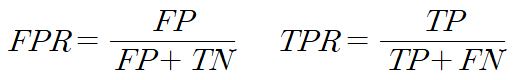
- AUC(Area Under Cruve)
- 평가 모델의 ROC 곡선의 하단 면적을 의미
- 랜덤일 때 0.5 값으로 ROC 곡선이 직선에서 멀어질수록 성능이 뛰어난 것으로 해석
지도학습 - 회귀 모델 평가 지표
- 실제값과 회귀 예측값의 차이를 기반으로 성능지표 수립, 활용
- SSE(Sum Squared Error) : 제곱의 합, 실제값과 예측값의 차이를 제곱하여 더한 값
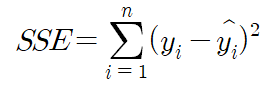
- MSE(Mean Squared Error) : 평균 제곱 오차, 실제값과 예측값의 차이의 제곱에 대한 평균을 취한 값

- RMSE(Root Mean Squared Error) : MSE에 루트를 취한 값, 평균제곱근 오차
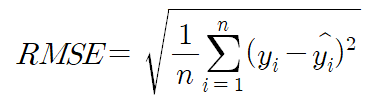
- MAE(Mean Absolute Error) : 실제값과 예측값 차이의 절대값을 합한 평균간
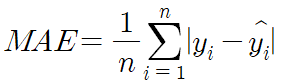
- 결정계수 R² : 회귀모델이 실제값에 대해 얼마나 잘 적합하는지에 대한 비율
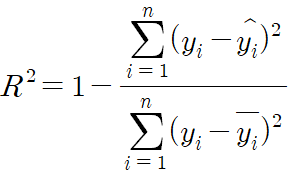
- Adjusted R²(수정된 결정계수) : 다변량 회귀분석에서 독립변수가 많아질수록 결정계수가 높아지는 것을 보완한 결정계수로 표본크기(n)와 독립변수의 개수(p)를 추가적으로 고려하여 분모에 위치시킴으로써 결정계수 값의 증가도를 보정
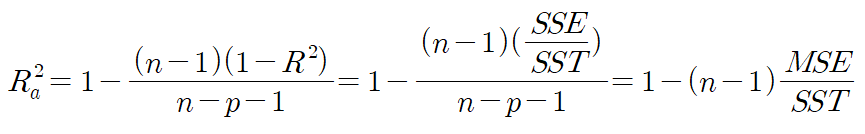
- MSPE(Mean Square Percentage Error) : MSE를 퍼센트로 변환한 값
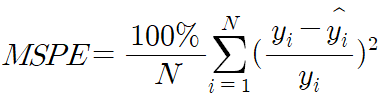
- MAPE(Mean Absolute Percentage Error) : MAE를 퍼센트로 변환한 값
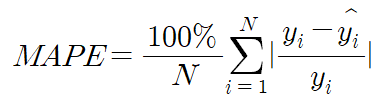
- RMSLE(Root Mean Squared Logarithmic Error) : RMSE를 로그를 취한 값으로 이상치에 덜 민감함
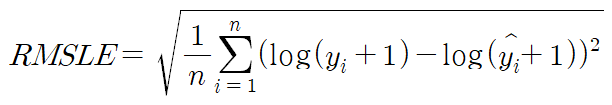
- AIC(Akaike Information Criterion) : 최대 우도에 독립변수의 개수에 대한 손신분을 반영하는 목적으로 모형과 데이터의 확률 분포 차이를 측정하는 것, 값이 낮을수록 모델의 적합도가 높아짐

- BIC(Bayes Information Criteria) : AIC와 동일한 목적을 지니나 주어진 데이터에서 모델의 우도를 측정하기 위한 값에서 유도된 지표, 변수 개수가 많을수록 AIC보다 더 페널티를 가함
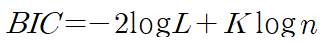
* K : 모델 파라미터의 개수(모델에서 상수항을 포함한 설명변수의 개수)
* L : log-Likelihood, 모델 적합도를 나타내는 척도
비지도 학습 - 군집 분석 평가 지표
- 지도학습과 달리 실측자료에 라벨링이 없으므로 모델에 대한 성능 평가의 어려움 존재
- 군집 분석에 한해 다음과 같은 성능 평가 지표 참고
- 실루엣 계수(Silhouette Ceofficient)
- a(i) : i번째 개체와 같은 군집에 속한 요소들 간 거리들의 평균
- b(i) : i번째 개체가 속한 군집과 가장 가까운 이웃군집을 선택 계산한 값
- 실루엣 계수가 1에 가까우면 근처의 군집과 더 멀리 떨어진 것(효율적으로 분리된 것)
- 실루엣 계수가 0에 가까우면 근처의 군집과 가까워진다는 것
- 실루엣 계수가 -이면 아예 다른 군집에 데이터 포인트가 할당된 것
- a(i)가 0이면 하나의 군집에서 모든 개체들이 붙어 있는 경우로 실루엣 지표가 0.5보다 클 시 적절한 군집 모델로 평가

- Dunn Index
- 군집 간 거리의 최소값을 분자, 군집 내 요소 간 거리의 최대값을 분모로 하는 지표
- 군집 간 거리는 멀수록, 군집 내 분산은 작을 수록 좋은 군집화로 Dunn Index 값은 클수록 좋음
- Dunn Index : 군집간 거리 최소값 / 군집내 요소간 거리 최대값
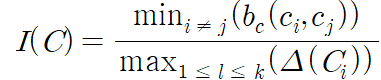
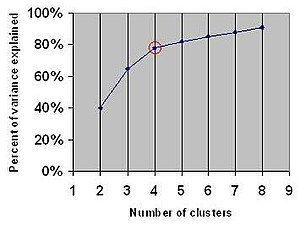
- 팔꿈치 기법(Elbow Method)
- 팔꿈치(Elbow) 모습을 나타내는 곳 값을 적절한 군집 K값으로 지정
참고
반응형