


반응형

# 판다스 외부 모듈 호출하기
import pandas- import가 되지 않을 경우
- 명령 프롬프트에서 pip install pandas 입력
- 주피터 노트북일 경우 !pip install pandas 코드 실행
# 판다스 데이터프레임 엑세스하기 (이하 데이터프레임 'df'로 서술)
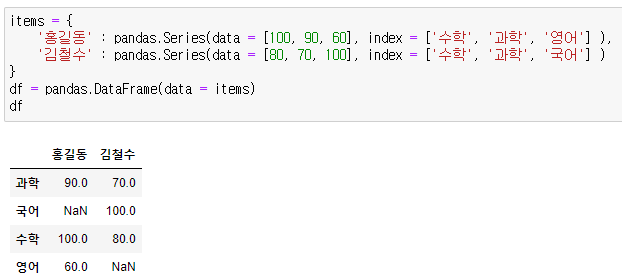
- 직접 접근하기 : df['칼럼명']
- 인덱스와 컬럼으로 접근하기 : df.loc['인덱스명', '칼럼명']
- 여러 데이터를 부를 땐 슬라이싱으로 범위를 지정
- 슬라이싱 할 때 주의점 : 번호로 할때는 끝나는 숫자 전까지이지만, 문자열일 경우는 해당 문자열까지 포함
- 인덱스의 번호로 접근하기 : df.iloc['인덱스의번호', '칼럼의번호']
- 다른 언어의 배열 접근법과 비슷

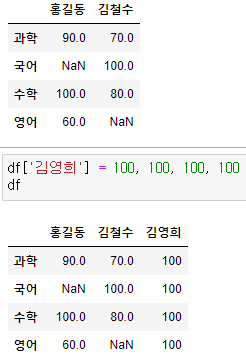
# 데이터프레임 항목 추가하기
직접 추가하기 > df[값] = 값
- 칼럼 추가해보기
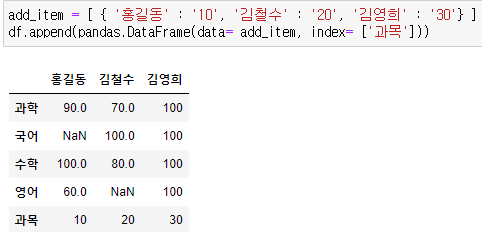
append로 추가하기 > df.append(값)
- 주의 : 추가 할 값이 기존의 칼럼명과 일치하지 않으면 새로운 칼럼을 생성
- 주의2 : 칼럼 추가시 인덱스명을 지정해주지 않아도 차례로 입력
- 인덱스 추가해보기
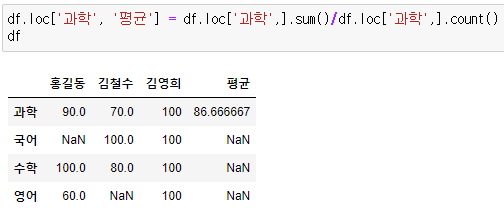
칼럼끼리의 값을 이용해 새로운 칼럼 만들기
- 칼럼끼리도 연산이 가능, 필요에 따라 데이터를 새로이 재가공 할 수 있음
- 점수의 평균을 구해 새로운 칼럼에 값 넣어보기
# 데이터프레임 수정하기
NaN값 0으로 수정하기
- df.fillna(n)

기존의 값 수정하기
- 바꿀 값의 위치 = 바꿀 값 ( loc, iloc, 칼럼명 셋 다 동일)
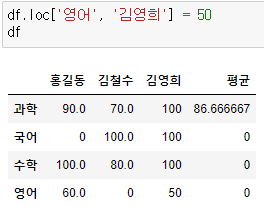
replace를 이용하여 값 수정하기
- df.replace( 기존 값, 바꿀 값) : 기존의 값을 바꿀 값으로 변경
- 예시) 0의 값 존재시 모든 0의 값을 NaN으로 변경

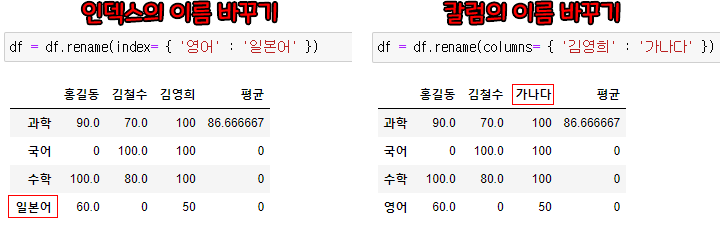
- 인덱스 이름과 칼럼 이름 수정하기
- df.rename(index/columns = { 기존이름 : 바꿀이름 }) : 기존 이름을 바꿀 이름으로 변경
# 데이터프레임 삭제하기
인덱스(행) / 칼럼(열) 삭제하기 (drop)
- df.drop('삭제항목', axis=n, inplace=False)
- axis = 0 > 행, 즉 인덱스를 뜻함
- axis = 1 > 열, 즉 칼럼을 뜻함
- inplace > 원본 데이터에 바로 반영하는지 유무, True로 하면 해당 데이터프레임에 삭제한 데이터 바로 반영

# 그룹별로 보기
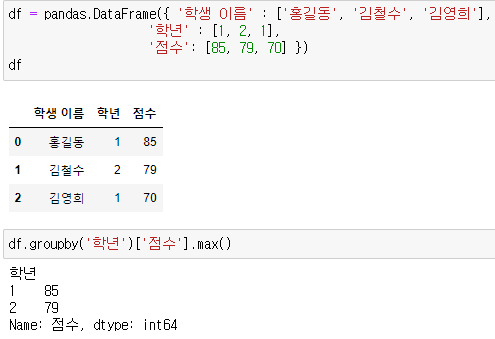
데이터를 카테고리별로 묶어서 데이터 추출하기 (groupby)
- df.groupby('그룹')['대상값'].수행함수 : 대상 값들을 함수 조건을 수행 후 그룹별로 보기
- 예시) 학년별로 가장 높은 점수 확인하기
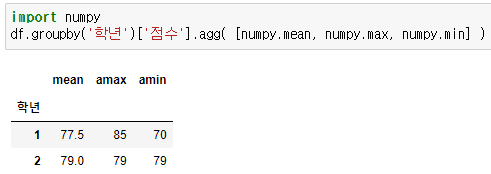
그룹별 다중 집계 작업하기 (Aggregation)
- groupby.agg(함수) : 그룹을 한번에 여러 연산을 수행하고 결과 값을 출력
- 예시) 학년별로 평균과 최고점수, 최저점수 출력
- 주의 : import numpy 확인
반응형