


반응형

Numpy 외부 모듈(라이브러리)을 활용해보자 - 1
# Numpy(넘파이) 란?
- 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리
# 넘파이의 특징
- 배열 데이터 구조 파악 및 연산
- 수치 계산을 위해 효율적으로 구현된 기능 제공
# 넘파이 외부 모듈 호출하기
import numpy as np
# 넘파이 모듈 호출, 편의상 np로 사용
#넘파이 호출시 에러가 난다면?
- 모듈 설치가 되어있지 않을 경우
- 콘솔 창에서 'PIP install 패키지명' 한 줄로 외부 모듈 설치 가능
ex) pip install numpy - jupyter notebook일 경우, 명령어 앞에 !(느낌표)를 붙여서 설치 가능
ex) 노트북에서 !pip install numpy 명령어 실행 - anaconda일 경우, anaconda navigator에서 설치 가능
- 콘솔 창에서 'PIP install 패키지명' 한 줄로 외부 모듈 설치 가능
- import numpy 를 하지 않은 경우
- import numpy의 코드를 먼저 실행
- import numpy as 로 다른 축약어를 정했으나 다른 문자열을 사용하는 경우
- 수행하는 코드를 축약어에 맞게 수정 <-> 축약어를 수행하는 코드에 맞게 수정
# 넘파이를 이용하여 배열 다루기
배열 생성하기 (Array/Arange/Full/Randint)
- numpy.array(n) : n의 값을 가지는 배열을 생성
numpy.array( [1, 2, 3] )
>>> array([1, 2, 3])
# 1차원 배열
numpy.array( [[1,2] , [3,4]] )
>>>
[[1 2]
[3 4]]
# 2차원 배열 생성
- numpy.arange(시작값, 끝값, 단계) : (=start:end:step)
- 시작값부터 끝값까지의 정수형의 배열 생성
- 단계의 기본값은 1이며 변경을 통해 수치 조정이 가능
numpy.arange(4, 10)
>>> array([4, 5, 6, 7, 8, 9])
# 4부터 9까지의 1차원 배열 생성
- numpy.linspace(시작값, 끝값, 갯수) : (=start:end:n)
- 시작값부터 끝값까지의 실수형 배열 생성
- 범위의 수를 갯수에 맞춰 자동으로 계산하여 생성
numpy.linspace(0, 5, 5)
>>> array([0. , 1.25, 2.5 , 3.75, 5. ])
# 0~5까지의 실수형 배열 생성
# 해당 범위를 갯수에 따라 균등히 수치를 나눔
numpy.linspace(0, 5, 5, endpoint=False)
>>> array([0., 1., 2., 3., 4.])
# endpoint를 False로 하면 마지막 값은 제외
# 0~4까지 총 5개의 수를 5개로 생성
# 소수점은 필요없지만 실수형 생성이기때문에 소수점을 가지고 있음
- numpy.full(갯수, 들어갈값) : 갯수만큼 특정값으로만 구성된 배열 생성
- zeros와 같이 특정 값으로만 채워 생성하는 함수도 있지만 full 하나로 다 표현 할 수 있다.
numpy.full( (2,3) , 6 )
>>> array([[6, 6, 6],
[6, 6, 6]])
# 2x3의 크기를 가지는 2차원 배열
# 값을 6으로만 채워서 생성
- numpy.random.randint(시작값, 끝값, 생성갯수) : 시작값부터 끝값까지의 임의숫자를 갯수만큼 배열 생성
- random를 사용하면 0~1 사이의 실수의 값으로 배열이 생성
numpy.random.randint( 1, 6, (3,4) )
>>> array([[4, 1, 2, 3],
[2, 4, 3, 2],
[5, 2, 2, 5]])
# 임의의 값을 가지는 3x4 2차원 배열 생성- + 번외) 정규분포를 만족하는 랜덤 배열 만들기 : normal(평균, 표준편차, 인덱스(갯수+1))
numpy.random.normal( 170, 10, 3 )
# normal(평균, 표준편차, 갯수)
>>> array([157.82605508, 174.78510514, 173.80221458, 162.67115586])
배열의 총 갯수 확인하기 (Size)
- numpy.size : 해당 배열이 갖는 값의 갯수 확인
numpy.array( [1, 2, 3] ).size
>>> 3
# 넘파이에서는 len이 아닌 size를 사용
# 배열이 갖는 값의 갯수
배열의 데이터타입(자료형) 확인하기 (Dtype)
- numpy.dtype : 배열이 갖는 값의 데이터타입 확인
numpy.array( [1, 2, 3] ).dtype
>>> dtype('int32')
# 숫자이기 때문에 데이터타입은 정수형(int)
# 컴퓨터에 따라 int32/int64가 출력
배열의 크기 확인하기 (Shape)
- numpy.shape : 해당 배열이 갖는 크기 확인
numpy.array( [[1,2] , [3,4]] ).shape
>>> (2, 2)
# 배열의 크기 확인, 2행 2열
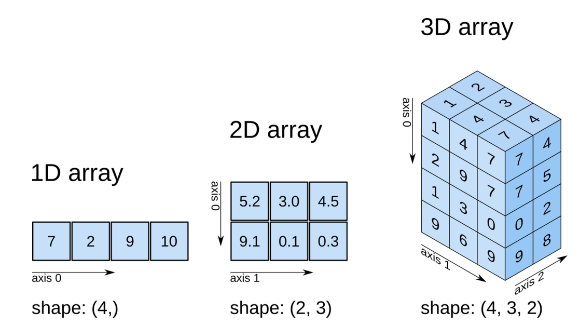
배열의 형태 바꾸기 (Reshape)
- reshape(n) : n의 형태로 기존의 배열을 변경, 배열의 갯수가 맞지 않으면 에러 출력
numpy.array( [1, 2, 3, 4] ).reshape( 2,2)
>>> array([[1, 2],
[3, 4]])
# 1차원 배열을 2차원 배열로 변환
# 변환시 배열 크기와 값의 갯수를 동일하게 설정
배열이 몇차원인지 확인하기 (Ndim)
- numpy.ndim : 해당 배열이 몇차원인지 확인
num1 = numpy.arange(5,30).reshape(5, 5)
print(num1)
>>> array([[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]])
# 2차원 배열 5x5 생성
num1.ndim
>>> 2
# 2차원 배열 확인
배열의 총 합, 최대값, 최소값, 평균값 구하기 (Sum, Max, Min, Mean) + 인덱스확인(Arg)
a = numpy.array( [1, 2, 3] ) # 1차원 배열 생성
print( "총 합 :" , a.sum() ) # 배열의 총 합
print( "최대값 :" , a.max() ) # 배열의 최대값
print( "최소값 :" , a.min() ) # 배열의 최소값
print( "평균값 :" , a.mean() ) # 배열의 평균값
>>> 총 합 : 6
최대값 : 3
최소값 : 1
평균값 : 2.0
# arg 를 넣어 해당 값의 인덱스를 확인 가능
print("최대값의 인덱스 :", a.argmax() ) # 최대값을 가지고 있는 배열의 인덱스
print("최소값의 인덱스 :", a.argmin() ) # 최대값을 가지고 있는 배열의 인덱스
>>> 최대값의 인덱스 : 2
최소값의 인덱스 : 0
배열 각 행/열 별로 수치 계산하기 (Axis)
- numpy.함수(axis=n) : 행/열을 기준으로 배열에 함수를 실행
- axis=0 : 행(세로) 기준 / axis=1 : 열(가로) 기준
x = numpy.arange(1, 17).reshape(4, 4)
x
>>> array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
# 4x4 2차원 배열 생성
x.max( axis = 1)
>>> array([ 4, 8, 12, 16])
# 각 열별로 최대값 구하기
x.argmax( axis = 0)
>>> array([3, 3, 3, 3], dtype=int64)
# 각 행별로 최대값의 인덱스 구하기
특정 조건을 만족하는 배열의 값/불(bool)값 불러오기
정말 간단하지만 혼동이 많으므로 꼭 유의!!!
- 특정 조건을 만족하는 값 불러오기
- 변수[조건]의 수식을 만족하지 않으면 불 값이 리턴
- 불 값을 이용하여 유효한 조건의 갯수를 확인 가능
x = numpy.arange(1, 17).reshape(4, 4)
# 1~16까지의 수가 담긴 배열 생성
# x[x>10]과 x>10의 차이 알기
x[x>10]
>>> array([11, 12, 13, 14, 15, 16])
# x[x>10] 10보다 큰 값 호출
x>10
>>> array([[False, False, False, False],
[False, False, False, False],
[False, False, True, True],
[ True, True, True, True]])
# x>10 10보다 큰 값이 아닌 모든 값을 bool값으로 반환
# 불 값을 이용하여 카운팅
(x>10).sum() #True=1, False=0 이므로 1의 값을 더하면 카운팅이 됨
>>> 6
# 10보다 큰 값은 6개가 존재함을 확인
배열 저장하기/불러오기 (Save/Load)
- numpy.save(''파일명", 배열) : 현재 실행중인 소스코드 파일의 같은 디렉토리에 "파일명.npy" 파일 생성
a = numpy.array( [ [1,2], [3,4] ] )
# 2x2의 크기를 갖는 2차원배열 생성
numpy.save('my_array', a)
# 생성한 배열을 my_array 파일로 저장- numpy.load("파일명") : 저장된 넘파이 파일의 배열 불러오기
b = numpy.load('my_array.npy') # 호출시 반드시 확장자(.npy) 입력
b
>>> array([[1, 2],
[3, 4]])
# 정상 호출 확인
반응형