


반응형

머신러닝이란?
- 일반적인 정의
- 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게하는 연구 분야
- 공학적인 정의
- 어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것
- 훈련 세트(training set) : 시스템이 학습하는 데 사용하는 샘플
- 훈련 사례(training instance) : 훈련 사례 (혹은 샘플)
- 훈련 데이터(training data) : 예를 들면 스팸 메일 분류에서 작업T는 새로운 메일이 스팸인지 구분하는 것, 경험 E는 훈련 데이터
- 성능 측정 P : 직접 정의, 스팸 메일 분류에서 정확히 분류된 메일의 비율을 P로 사용
- 정확도(accuracy) : 성능 측정의 척도, 분류 작업에 자주 사용
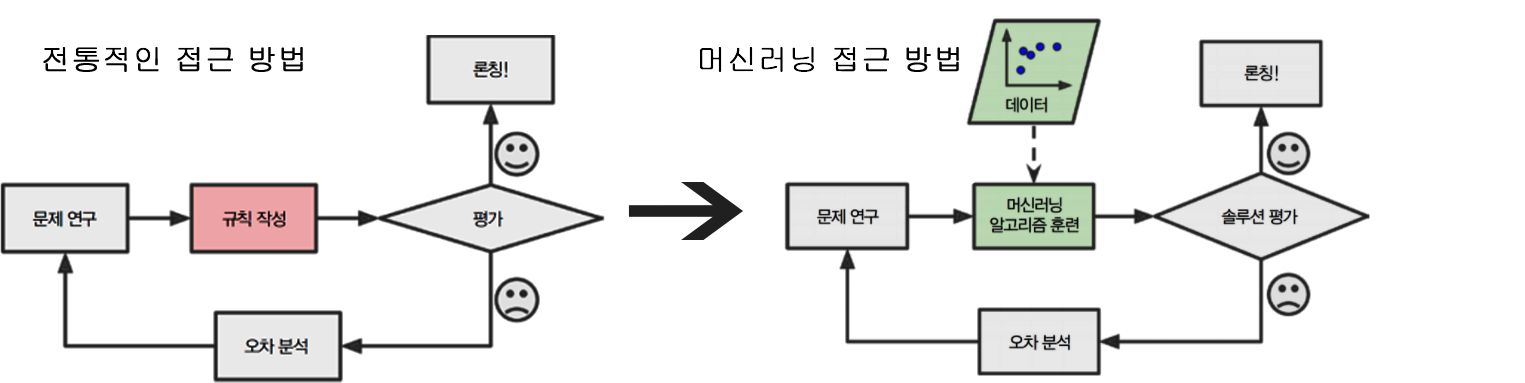
머신러닝을 사용하는 이유?
- 전통적인 접근 방법 : 문제가 생기면 문제 해결을 위한 규칙이 점점 길어지고 복잡해지므로 유지 보수가 어려움
- 머신러닝 접근 방법 : 머신러닝을 사용하면 프로그램이 훨씬 짧아지고 유지 보수하기 쉬우며 대부분의 정확도가 높음
- 데이터 마이닝(data mining) : 머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견하는 과정
머신러닝의 종류
- 지도, 비지도, 준지도, 강화 학습 : 사람의 감독하에 훈련하는 것인지 그렇지 않은 것인지
- 온라인 학습과 배치 학습 : 실시간으로 점진적인 학습을 하는지 아닌지
- 사례 기반 학습과 모델 기반 학습 : 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자들이 하는 것처럼 훈련 데이터셋에서 패턴을 발견하여 예측 모델을 만드는지
1-1. 지도 학습
- 지도 학습(supervised learning) : 알고리즘에 주입하는 훈련 데이터에 레이블(label)이라는 원하는 답이 포함된 것
- 분류(classification) : 훈련 데이터로 훈련되어야 하며 어떻게 분류할지 학습하는 것 (예: 스팸 필터)
- 회귀(regression) : 예측 변수(predictor variable)라 부르는 특성(feature)을 사용해 타깃(target) 수치를 예측 하는 것 (예: 중고차 가격, 특성(주행거리, 연식, 브랜드 등) / 타깃(중고차 가격)
- 로지스틱 회귀(logistic regression) : 분류 알고리즘을 회귀에 사용 할 때 널리 쓰이는 지도 학습 알고리즘 (예: 스팸일 가능성 20%)
- 지도 학습의 알고리즘 종류
- k-최근접 이웃(k-nearest neighbors)
- 선형 회귀(linear regression)
- 로지스틱 회귀(logistic regression)
- 서포트 벡터 머신(support vector machine)(SVM)
- 결정 트리(decision tree)와 랜덤 포레스트(random forest)
- 신경망(neural networks)
1-2. 비지도 학습
- 비지도 학습(unsupervised learning) : 훈련 데이터에 레이블이 없는 것, 즉 시스템에 아무런 도움 없이 학습해야 하는 것
- 비지도 학습의 알고리즘 종류
- 군집(clustering) : 각 그룹을 더 작은 그룹으로 세분화하는 것
- k-평균(k-means)
- DBSCAN
- 계층 군집 분석(hierarchical cluster analysis(HCA)
- 이상치 탐지(outlier detection)와 특이치 탐지(novelty detection)
- 이상치 탐지 : 데이터셋에서 이상한 값을 자동으로 제거하는 것
- 특이치 참조 : 훈련 세트에 있는 모든 샘플과 달리 보이는 새로운 샘플을 탐지하는 것
- 원-클래스(one-class SVM)
- 아이솔레이션 포레스트(isolation forest)
- 시각화(visualization)와 차원 축소(dimensionality reduction)
- 시각화 : 레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어주는 것
- 차원 축소 : 너무 많은 정보를 잃지 않으면서 데이터를 간소화하는 것, 두 특성을 하나의 특성으로 합침(특성 추출(feature extraction))
- 주성분 분석(principal component analysis)(PCA)
- 커널(kernel) PCA
- 지역적 선형 임베딩(locally-linear embedding)(LLE)
- t-SNE(t-distributed stochastic neighbor embedding)
- 연관 규칙 학습(association rule learning) : 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 것
- 어프라이어리(Apriori)
- 이클렛(Eclat)
- 군집(clustering) : 각 그룹을 더 작은 그룹으로 세분화하는 것
1-3. 준지도 학습
- 준지도 학습(semisupervised learning) : 레이블이 없는 샘플과 레이블된 샘플, 일부만 레이블이 있는 데이터를 다루어 학습하는 것
- 비지도 학습의 알고리즘 종류 (대부분의 준지도 학습 알고리즘은 지도 학습과 비지도 학습의 조합으로 구성)
- 심층 신뢰 신경망(deep belief netword)(DBN)
- 제한된 볼츠만 머신(restricted Bolzmann machine)(RBM) : 비지도 학습으로 순차적으로 훈련된 다음 전체 시스템이 지도 학습 방식으로 세밀하게 조정하는 것
1-4. 강화 학습
- 강화 학습(reinforcement learning) : 환경을 관찰해서 행동을 실행하고 그 결과로 가장 큰 보상을 얻기 위해 최상의 전략을 스스로 학습하는 것 (예: 알파고)
- 에이전트 : 학습하는 시스템
- 보상 : 환경을 관찰해서 행동을 실행한 결과
- 정책 : 시간이 지나면서 가장 큰 보상을 얻기 위한 전략
2-1. 배치 학습
- 배치 학습(batch learning)
- 시스템이 점진적으로 학습 불가, 가용한 데이터를 모두 사용해 훈련 시키는 것
- 일반적으로 시간과 자원을 많이 소모하므로 보통 오프라인 학습 수행, 즉 학습한 것을 단지 적용만 함
- 오프라인 학습(offline learning) : 먼저 시스템을 훈련시키고 시스템에 적용하여 더 이상의 학습 없이 실행하는 것
2-2. 온라인 학습
- 온라인 학습(online learning)
- 데이터를 순차적으로 한 개씩, 또는 작은 묶음(미니 배치(mini-batch)) 단위로 주입하여 시스템을 훈련시키는 것
- 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습 가능
- 외부 메모리(out-of-core) 학습 : 컴퓨터 한 대의 메인 메모리에 들어갈 수 없는 아주 큰 데이터셋을 학습 할 때 알고리즘이 데이터 일부를 읽어 들이고 훈련 단계를 수행하여 전체 데이터가 모두 적용할 때까지 과정을 반복하는 것
- 학습률(learning rate) : 변화하는 데이터에 얼마나 빠륵 적응할 것인지의 척도
- 학습률을 높게 하면 시스템이 데이터에 빠르게 적응하지만 예전 데이터를 금방 잊어버림
- 반대로 학습률이 낮으면 시스템의 관성이 더 커져서 더 느리게 학습
- 온라인 학습의 가장 큰 문제점은 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 점진적으로 감소
3-1. 사례 기반 학습과 모델 기반 학습
- 사례 기반 학습(instance-based learning) : 유사도를 측정해서 새로운 데이터와 학습한 샘플을 비교하여 일반화하는 것
- 모델 기반 학습(model-based learning) : 샘플들의 모델을 만들어 예측에 사용하는 것
반응형